Biomolekulare Rechner
Der technische Einsatz ist nicht mehr fern
Vor etwa 60 Jahren dachten sich Konrad Zuse und Helmut Schreyer Relaisschaltungen für einfache binäre Rechenoperationen aus. Aus elektrotechnischer Sicht waren diese Schaltungen nicht interessant; komplexe Relaisschaltkreise für Telefonvermittlungen waren üblich. Auch aus mathematischer Sicht beeindruckten die Rechenergebnisse nicht, ein Rechenschieber konnte weit mehr.
Den Pionieren der digitalen Computertechnik war jedoch klar, ein neues Prinzip entdeckt zu haben, das sich ausbauen ließ. Konrad Zuse notierte in seinem Tagebuch, daß sich alle Berechnungen in die elementaren Schritte zerlegen lassen, für die er Schaltungen entwickelt hatte. Im gleichen Tagebucheintrag vom 19. Juni 1937 verweist er auf die Ähnlichkeit zwischen der Entfaltung eines Rechenprozesses und der Entwicklung einer Keimzelle.1
DNA-Moleküle, die Träger der Erbinformation in Keimzellen, sind 57 Jahre später die Grundlage für ein Experiment geworden, in dem Leonard Adleman ein mathematisches Problem aus der Graphentheorie mit Hilfe von molekularbiologischen Methoden löste.2 Aus biochemischer Sicht war dieses Experiment allerdings nicht interessant, die verwendeten Methoden sind Standard für Biochemiker. Auch aus mathematischer Sicht beeindruckte das Ergebnis nicht. Ein programmierbarer Taschenrechner hätte die Lösung wesentlich schneller gefunden.
War hier dennoch ein neues Prinzip entdeckt worden, das sich ausbauen läßt? Ist es möglich, Milliarden von kurzen DNA-Molekülen gleichzeitig an der Lösung eines Problems zu beteiligen und mit Hilfe dieser enormen Parallelität moderne Supercomputer in den Schatten zu stellen? Diese Fragen versuchen Molekularbiologen, Mathematiker, Informatiker und Biochemiker seither in einer Flut von Artikeln zu beantworten.
So viel ist sicher, Moleküle eignen sich als Bausteine für Informationsverarbeitungssysteme - den Beweis dafür tragen wir im Kopf. Wie allerdings in biologischen Systemen die Informationsverarbeitung auf molekularer Ebene funktioniert, ist bisher nicht aufgeklärt. Kein Zweifel besteht daran, daß sich natürliche biomolekulare Computer völlig andere physikalische Prinzipien zunutze machen als konventionelle Computerarchitekturen.
Computer in der Form, wie wir sie heute kennen, gehen zurück auf das Ziel, das mühsame und stumpfsinnige Berechnen von Tabellen (wie etwa trigonometrische oder astronomische Tafeln) zu automatisieren. Unsere heutigen Computer sind konkurrenzlos in ihrer ursprünglichen Aufgabe. Schon die frühen Computer waren jedoch universell verwendbar, d. h. jedes von einem Computer lösbare Problem könnte im Prinzip mit diesen Geräten gelöst werden, vorausgesetzt der Maschine würde genug Speicherplatz und Zeit zur Verfügung stehen. Diese von Alan Turing formal gezeigte, universelle Verwendbarkeit führte zusammen mit der ständigen Verbesserung in Speicherplatz und Rechengeschwindigkeit dazu, daß das grundlegende Prinzip nur selten in Frage gestellt wurde. Der technische Fortschritt konzentrierte sich auf quantitative Verbesserungen - neue Konzepte wurden kaum in Erwägung gezogen.
Als Ergebnis dieser Entwicklung stehen uns heute im wesentlichen Prozessoren zur Verfügung, die nichts anderes sind als groteske Parodien mechanischer Rechner, wie sie von Charles Babbage und, ein Jahrhundert später, von Konrad Zuse entwickelt worden waren. Auch wenn im Prinzip alles Berechenbare mit dem herkömmlichen Rechnerkonzept bei nicht-endendem Fortschritt in Speicherkapazität und Rechengeschwindigkeit eines Tages berechnet werden könnte, heißt das nicht, daß konventionelle Computer für jede Art von Informationsverarbeitung das geeignete Werkzeug sind. In Anwendungsbereichen, die nicht mehr viel mit dem Berechnen von Tabellen gemeinsam haben, tun sich Computer schwer, zufriedenstellende Resultate zu liefern.
Gibt es Alternativen? Um dieser Frage nachzugehen, ist es zunächst einmal nützlich, Computer technologieunabhängig zu definieren. Ein Computer ist, im weitesten Sinne, ein System, welches von einem als Problembeschreibung interpretierbaren Augangszustand den Naturgesetzen folgend in einen als Problemlösung interpretierbaren Zustand übergeht. Anders ausgedrückt: Computeranwender betrachten auf dem Bildschirm nichts anderes als Meßwerte von einem komplizierten elektrodynamischen Experiment, das sie mit ihrer Computerapparatur ausführen, und interpretieren diese Werte dann etwas eigenwillig. Umgekehrt können in einem wissenschaftlichen Experiment die festgelegten Parameter als Problembeschreibung und die gemessenen Werte als Lösungen, d.h. das Experiment als Berechnung, angesehen werden. Wenn sich eine Interpretation der Systemzustände finden läßt, die über das Verhalten des Systems selbst hinausgeht, so kann das System zur Informationsverarbeitung herangezogen werden. Dies ist zum Beispiel der Fall für bestimmte optische Einrichtungen und analoge Schaltkreise, die dann entsprechend als optische Computer oder Analog-Computer bezeichnet werden.
Anfang der 70er Jahre begannen Ephraim Liberman in Rußland und Michael Conrad in den U.S.A. sich mit der potentiellen Rolle von Biomolekülen in Informationsverarbeitungssysytemen auseinanderzusetzten. Biomoleküle sind makromolekulare Strukturen mit sehr spezifischer Funktion. Zusammengesetzt aus einer kleinen Menge einheitlicher Grundbausteine ergibt sich durch deren Kombination eine Vielfalt an möglichen Strukturen. Entscheidend für die Funktion der typischerweise aus mehreren tausend Atomen bestehenden Makromoleküle ist die Raumanordnung ihrer flexibel verbundenen Grundbausteine. Bestimmt wird diese, als Konformation bezeichnete Raumanordung von elektrostatischen Einflüssen der zum Makromolekül gehörenden Atome untereinander und elektrostatischen Einflüssen von Molekülen und Ionen in der Umgebung des Makromoleküls.
Die Tatsache, daß die Funktion von Biomolekülen von deren Konformation und diese wiederum sehr spezifisch von der Umgebung des Biomoleküls abhängt, wird in Biosensoren ausgenutzt. Außer Konformationsänderungen können elektrostatische Kräfte auch die spezifische Zusammenlagerung von Makromolekülen bewirken. Darauf basiert L. Adlemans DNA-Computerprinzip.
Verlockend am Einsatz von Biomolekülen ist ihre geringe Größe. Der Abstand beispielsweise zwischen den Dotierungsatomen in einem herkömmlichen Silizumhalbleiter ist größer als manche (biologische) Viren. Es gibt Zellen, die zur Steuerung ihres Stoffwechsels und der Verarbeitung ihrer Erbinformation weniger Platz benötigen, als ein einziges logisches Gatter auf einem Chip einnimmt3 Interessanter als die mit herkömmlichen Halbleitern unerreichbare Integrationsdichte ist allerdings ein anderer Aspekt der Größe von Makromolekülen. Sie liegen an der Grenzlinie zwischen makroskopischer und mikroskopischer Physik und sind damit als Schnittstelle zwischen makroskopischer Informationsverarbeitung und quantenmechanischer Parallelität ideal geeignet.
Biomoleküle können also als hochintegrierte Komponenten betrachtet werden, die auf Signale aus ihrer Umgebung mit der Veränderung ihres Konformationszustandes reagieren (Abb 1). Abhängig vom verwendeten Molekül, kommen optische, chemische oder elektrische Eingangssignale in Frage. Auch die Erkennung des Konformationszustandes kann optisch (z.B. durch Absorbtionsänderung oder Fluoreszenz), chemisch (bei katalytisch aktiven Proteinen) oder elektrisch (z.B. in Verbindung mit Feld-Effekt-Transistoren) erfolgen.


Man könnte jetzt daran denken, solche Komponenten zu einer Art biologischem Schaltkreis zusammenzusetzen, doch dabei ergäbe sich ein Problem. Da Makromoleküle sensitiv auf ihre Umgebung reagieren, können sie nicht als unabhängige Module betrachtet werden. Das Zusammenspiel der Makromoleküle hängt von den elektrostatischen Wechselwirkungen von Tausenden von Atomen ab und läßt sich nicht vorhersagen. Würde man die Komponenten voneinander isolieren, so bliebe die wesentliche Eigenschaft der Makromoleküle ungenutzt. Das Ergebnis wäre nur eine weitere Version des mechanischen Rechnerkonzepts, das den herkömmlichen auf Festkörperphysik beruhenden Computern zugrunde liegt.
Die Kontextabhängigkeit von Komponenten - in technischen Systemen so weit wie möglich gemieden - ist wesentlich für die Funktion biologischer Systeme. Natürliche Informationsverarbeitungssysteme müssen sich zwar, genau wie technische Systeme, den Anforderungen entsprechend verhalten, aber ihr Verhalten muß nicht planbar, d.h. nicht aus der Systembeschreibung vorhersagbar sein.
Effiziente biomolekulare Rechner, so argumentiert M. Conrad4, können nicht programmierbar sein. Vorraussetzung für die Programmierbarkeit wäre eine endliche Beschreibung des Verhaltens der Komponenten und diese wiederum wäre nur möglich wenn die Wechselwirkungen zwischen den Komponenten und damit die Effizienz beschränkt würde.
Programierbarkeit ist allerdings keineswegs notwendig. Beispielsweise sind künstliche Neuronale Netze im Allgemeinen nicht programmierbar. Ein biomolekulares System könnte in einer Evolutionsstrategie das vom Anwender gewünschte Verhalten erlernen. Bei der Entwicklung von Medikamenten wird die Evolution von Makromolekülen im Reagenzglas (genauer gesagt, in einem Plastikhütchen) bereits genutzt. Die Designphase eines herkömmlichen Systems würde also durch eine Lernphase für molekulare Komponenten ergänzt. Der rasante Fortschritt in Molekularbiologie und Biotechnologie macht solche, bisher nur theoretischen, Ansätze zunehmend praktikabler.
Welche Aufgabe könnten biomolekulare Komponenten übernehmen? Datenverarbeitung ist die Abbildung von Eingangs- auf Ausgangsdaten. Theoretisch könnte jede solche Abbildung als eine (nicht notwendigerweise endliche) Tabelle ausgedrückt werden. Computerprogramme sind relativ kurze Beschreibungen dieser meist unvorstellbar, und natürlich unausschreibbar, langen Tabellen. Die Menge aller möglichen kurzen Beschreibungen ist allerdings viel kleiner als die Menge aller möglichen langen Tabellen. Das heißt, es gibt viele Abbildungen von Eingangs- auf Ausgangsdaten, für die gar keine Programme existieren können.
Als zukünftiges Einsatzgebiet von Biomolekülen kommt die Implementierung von solchen Abbildungen in Frage, die entweder nicht in Form von Computerprogrammen ausgedrückt werden können oder die, als Programme ausgedrückt, für Echtzeitanwendungen zu langsam wären. Biomolekulare Informationsverarbeitung ist komplementär zu den Eigenschaften digitalelektronischer Computer, die Forschung zielt deshalb auf eine Kombination beider Technologien ab. Wie so etwas aussehen könnte ist in Abb. 2 dargestellt.
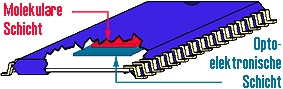
Niemand weiß, wie lange es dauern wird, bis man einen molekulare Co-Prozessor aus dem Katalog bestellen kann. Der technische Einsatz von Biomolekülen in der Informationsverarbeitung ist jedoch nicht mehr fern. Nobert Hampps Arbeitsgruppe an der Philipps-Universität in Marburg ist mit ihrem optisch-biomolekularen Bildverarbeitungssytem wohl weltweit diesem Ziel am nächsten.
Basierend auf gentechnisch modifiziertem Bacteriorhodopsin, einem Protein, das bestimmten Bakterien sozusagen als Solarzelle dient, ist ihr Verfahren in der Lage, Holographie mit 25 Bildern pro Sekunde - also "life" - an eine Videokamera zu liefern. Da mit holographischen Methoden Bilder sehr schnell gegeneinander abgeglichen werden können, kann dies erheblichen Rechenaufwand auf einem herkömmlichen Computer einsparen.
Durch Licht bewirkte Zustandsänderungen sind die wesentliche Eigenschaft von Bacteriorhodopsin. Es kann zu optisch hochwertigen Filmen verarbeitet werden, in denen das Protein mehrere Millionen solcher Konformationsänderungen übersteht. Mit der Konformation des Proteins ändert sich auch seine Farbe (also sein Absorptionsspektrum). Das erlaubt zum einen, den aktuellen Zustand durch Licht auszulesen, und zum anderen, mit verschiedenfarbigem Licht (beispielsweise Lasern unterschiedlicher Wellenlänge) jeweils nur Proteine, die sich bereits in einem bestimmten Zustand befinden, zu beeinflussen (Abb. 3).

Als biologisches Flip-Flop mit optischen Ein- und Ausgangssignalen ist Bacteriorhodopsin auch für den Bau von Speichern interessant. Es wird erwartet, daß es noch in diesem Jahrtausend kommerziell eingesetzt wird.5 Der derzeitige Fortschritt bei Halbleiterlasern, integrierter Optik und der Entwicklung von komplexen Biosensoren (etwa DNA-Hybridisations-Chips) könnte dazu führen, daß in den nächsten Jahren hier und da etwas Weiches in der Hardware auftaucht. Ob es in ferner Zukunft möglich sein wird, einen PC während des Urlaubs in der Gefriertruhe aufzubewahren, oder man jemanden damit beauftragen muß, ihn regelmäßig zu füttern, ist derzeit allerdings noch nicht absehbar.
Klaus-Peter Zauner ist Mitglied der BioComputing Group an der Wayne State University.
Artur Schmidt: Quantencomputer
Weitere Informationen
Eine Vorstellung von den Konformationszuständen eines Proteins vermitteln sehr anschaulich die Trickfilme auf den Webseiten der Universität Freiburg. Details zum Protein Bacteriorhodopsin können hier gefunden werden. Zusammenfassungen über bestimmte Aspekte biomolekularer Rechner befinden sich auf den Web-Seiten des Molecular Computing Seminars, das Wolfgang Banzhaf und Peter Dittrich an der Universität Dortmund veranstalteten. Die Webseite der International Society for Molecular Electronics and BioComputing enthält Konferenzankündigungen und eine (unvollständige) Liste mit Links zu Arbeitsgruppen, die in diesem Bereich forschen (in Englisch).