Mikrorechner gegen Krebs
Mit winzigen Bio-Computern soll im menschlichen Körper entstehender Krebs früh erkannt werden. Dies könnte sogar die Möglichkeit eröffnen, diese Krankheit initial zu bekämpfen.
Krebszellen unterscheiden sich deutlich von gesunden Körperzellen: Sie wuchern ohne Maß und Ziel, überfallen aggressiv die intakten Artgenossen. Aber sie verrichten ihr Zerstörungswerk zunächst in aller Stille. Zeit wirdŽs, dachten die israelischen Bioinformatiker um Ehud Shapiro vom Weizmann-Institut in Rehovot, Israel, endlich ein geeignetes „Frühwarnsystem“ zu realisieren.
Daher entwickelten die Forscher einen winzigen DNA-Rechner im Nanometermaßstab, der im menschlichen Körper Lungenkrebs und das Prostatakarzinom erkennen und auch bekämpfen soll (Nature, Bd. 429, Seite 423-429). Bisher führten die Wissenschaftler ihre Experimente außerhalb lebender Zellen in Petrischalen und ähnlichen Reaktionsgefäßen im Labor durch. Dank unvorstellbar kleiner Abmessungen passen etwa eine Billion solcher Kleinstroboter in einen einzigen Wassertropfen.


Vom Prinzip her handelt es sich um eine sehr kleinen Bioapparat, der wie ein Computer funktioniert, nur auf biochemischer Basis statt mit Elektronen. Bei der Entwicklung dieser Sonde machte sich das Team die Tatsache zunutze, dass sich Krebs im Körper durch bestimmte Boten-RNA (m-RNA) verrät: Manche Gene sind mutiert, so dass die nach ihrem Bauplan im Körper gebildeten Stoffe ihre Aufgabe nicht mehr korrekt erfüllen können. Teile dieser Eiweiße liegen dann in einer zu niedrigen Konzentration vor, wenn der Bildungsprozess gestört ist. Andererseits können die Stoffe auch in einer zu großen Menge existieren, wenn ihr Abbau nach erledigter Arbeit ins Stocken gerät. Beides kann die normale Zellfunktion aus dem Gleichgewicht bringen.
Der erste Schritt, um aus einem Genabschnitt ein körpereigenes Protein aufzubauen, besteht darin, eine Kopie der DNA-Daten als so genannte Boten-RNA herzustellen. Dies geschieht immer wieder in jeder Zelle. Um den genetischen Auslöser für die beiden Krebsarten nachzuweisen, brauchen die Forscher also nur die m-RNA aus entsprechenden Körperzellen zu entnehmen und auf krebsfördende Eigenschaften zu prüfen. Liegen diese bei der Mehrheit aller RNA-Moleküle vor, schaltet dieser kleine Biomechanismus in den Sonden von „Null“ auf „Eins“ und deutet somit auf eine Krebserkrankung. Jede der vielen DNA-Kleinstcomputer nimmt sich dabei ein ganz bestimmtes m-RNA-Molekül vor. Die konkrete Zuordnung, welche Biosonde auf welches dieser Moleküle trifft, geschieht zufällig. So analysiert jeder einzelne „Mikro-Rechner“ dann selbstständig „sein“ RNA-Teilchen und erzeugt eine Ja-Nein-Entscheidung. Aus der Gesamtheit aller Antworten ergibt sich die Krebsdiagnose.
Der Code der Basenfolge entscheidet alles
Zum Start ihres Experimentes injizierten die Wissenschaftler die Krebszellen in einer Testlösung mit den Mikrosonden. Damit lösten sie eine Reihe von Verarbeitungsschritten aus, die im Folgenden beschrieben werden: Zu Beginn der Analyse gelangt ein Boten-RNA-Molekül, das die genetische Information mit den potenziellen Krebsmerkmalen trägt, in die kleine Bio-Apparatur. Dort warten schon so genannte Kodierungsmoleküle, die aus einem kurzen Doppelstrang von DNA und einem überstehenden Einzelstrang – dem so genannten „klebrigem Ende“ (sticky end) – bestehen. Diese scannen die eingegebene RNA auf die krebsspezifische Sequenz der Nucleinsäure-Basen Adenin, Cytosin, Guanin und Thymin, suchen auf diese Weise, ob ein Defekt vorliegt oder nicht. Wobei diese „Wächtermoleküle“, die die Forscher eigens synthetisieren müssen, pro untersuchtem Gen in zwei Versionen existieren: eines für den Fall, dass ein Krankheitssymptom vorliegt, und jenes für den „Nein-Fall“. Je nachdem, welches der zwei bereitstehenden Kodierungsmoleküle sich passgenau an klebrigen Ende der RNA anlagert, entscheidet der Biomechanismus, ob ein Defekt vorliegt.
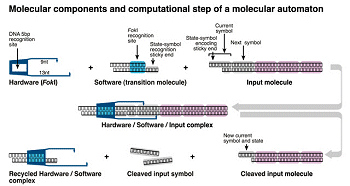
Das Kodierungsmolekül übersetzt das Resultat in einen spezifischen „Basencode“, der sich auf diesem Molekül befindet. Die Codes derjenigen Wächtermoleküle, die sich zuvor an die m-RNA angeheftet haben, tragen die auswertbaren DNA-Informationen, in welchen Genabschnitten welche Defekte vorkommen. Anschließend passieren diese genetischen Daten schrittweise einen speziellen DNA-Doppelstrang, der als „Diagnose-Molekül“ dient und von den Forschern speziell für die Sonde synthetisiert wurde. An den beiden Kettenenden dieses Moleküls sind zwei wichtige Fragmente angebracht: Auf der einen Seite ein Einzelstrangüberhang (sticky end), dessen spezielle Basenfolge komplementär zur „Ja-Kodierung“ ist. Damit können dort weitere Kodierungsmoleküle mit entsprechender genetischer Information anlegen. An seinem anderen Ende trägt das Diagnose-Molekül einen „Hairpin-Loop“ – eine Schleife in Haarspangenform. Sie verhindert, dass sich dort unerwünschte Reaktionspartner anlagern können. Darüber hinaus bietet diese Schleife einen geeigneten Platz für das rettende, krebsbekämpfende Medikament.
Bei Antwort „Ja“ wird Medikament frei
Pro Gen trägt diese DNA wiederum eine charakteristische Basensequenz, die im Fall einer positiven Entscheidung vom Kodierungsmolekül einfach „abgebissen“ wird. Auf diese Weise wird das Diagnose-Molekül schrittweise kürzer, bis schließlich nur noch die Schleife übrig ist. Deren Basenfolge lässt sich unmittelbar nutzen, um als Medikament zu wirken und an eine krankhafte Boten-RNA zu binden. Somit verhindert dieser „Arznei-DNA-Abschnitt“, dass aus krankhaft veränderter Boten-RNA Eiweiße wie beispielsweise das MDM2-Protein aufgebaut werden, das aggressives Zellwachstum fördert.
Damit aber das Kodierungsmolekül genau an die Diagnose-DNA „andocken“ kann, müssen die beiden „sticky ends“ zusammenpassen. Dabei bilden sich zunächst bei der so genannten Hybridisierung zwischen den Wasserstoff- und Sauerstoffatomen komplementärer Basen Wasserstoff-Brücken, schwache chemische Bindungen. Im nächsten Schritt schweißt das Enzym Ligase beide Biomoleküle zusammen, in dem es kovalente Phosphodiester-Bindungen zwischen der freien 5-Phosphatgruppe und der freien 3Ž-Hydroxylgruppe-Gruppe der Desoxyribose fördert. So kommt es zu einem verlängerten DNA-Strang. Diese festen Bindungen sind für den weiteren Ablauf des Verfahrens notwendig, da noch ein zweites Enzym beteiligt ist: das Restriktionsenzym FokI. Beide Biokatalysatoren arbeiten nach dem Schlüssel-Schloss-Prinzip.
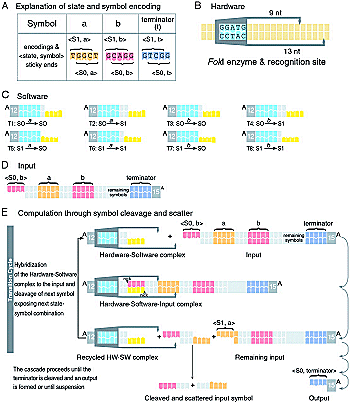
Weil das Enzym die charakteristische Basenfolge GGATG auf dem Kodierungsmolekül erkennt, setzt es sich dort fest. Das Ferment hat die Aufgabe, die zusammengeschweißte DNA-Einheit wieder zu spalten. Dies macht es aber an anderer, fest definierter Stelle des Doppelstrangs. So schneidet es weiter hinten, dass wieder ein neues „sticky end“ entsteht. Dieses Ende ist dann durch eine Basenfolge charakterisiert, die wiederum komplementär zur Ja-Information eines anderen Kodierungsmoleküls ist. Somit setzt sich dieser Kettenprozess weiter, so dass nach und nach alle abzuprüfenden Gendefekte der Boten-RNA am Diagnose-Molekül zur Auswertung gelangt sind. Hätten es die Forscher bei der Hybridisierung gelassen, könnte das Schneide-Enzym nicht arbeiten und die Kette wäre nach dem ersten Schritt abgebrochen.
Normalerweise gibt es zwei Möglichkeiten, wie der Prozess enden kann: Erstens, wenn alle Kodierungsmoleküle mit einer Ja-Kodierung mit dem Diagnose-Molekül reagieren konnten, so dass dieses bis auf den Loop abgebaut wurde. Hier sagt die Sonde „Ja“. Zum anderen, sobald ein Kodierungsmolekül, das den Basencode für einen negativen Befund trägt, an ein überstehendes Ende angreifen will. Da hier die sticky ends nicht passen, bleiben das Diagnose-Molekül intakt und das Medikament im Loop verborgen, es wird nicht gebraucht. Dies bedeutet die Antwort „Nein“.
Resultat sichtbar durch Gel-Elektrophorese
Im letzten Schritt der Krebsanalyse geben die Wissenschaftler die Diagnose-Moleküle aller eingesetzten Sonden in ein gemeinsames Elektrophorese-Gel, mit dem die Molekülmassen sehr exakt bestimmt werden können. Hierbei nutzen Forscher aus, dass DNA-Moleküle elektrisch geladen sind. Bei angelegter Gleichspannung wandern die Teilchen durch die Poren des Gels zum Pluspol. Die Geschwindigkeit ist von der Molekülmasse abhängig, so dass sich die Diagnose-Moleküle ihrer Länge entsprechend im Gel sortiert werden. Die Stellen, an denen sich nach Abschalten der Spannung Diagnose-Moleküle angereichert haben, lassen sich mit einem Marker einfärben. Eine positive Krebsdiagnose liegt dann vor, wenn sich an einem Ort im Gel, an dem kleine DNA-Fragmente erwartet werden, eine tiefe Färbung zeigt.
Die Kodierungs-DNA, an der das Restriktionsenzym sitzt, gewinnen die Wissenschaftler aus Israel zurück, in dem sie die Temperatur der Bio-Sonde entsprechend regeln. Denn die meisten Enzyme sind bei Körpertemperatur aktiv. Wird es heißer, zerfallen sie und die DNA bleibt als stabiler Reaktionspartner erhalten. Auf diese Weise kann sie wieder am Prozess teilnehmen. Leider hat der molekulare Winzling bislang einen großen Nachteil: Egal, wie die Diagnose ausfällt, arbeitet er nur ungefähr eine Stunde, dann zersetzt sich die Boten-RNA.
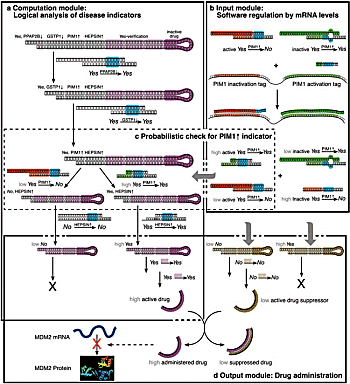
Der Vorteil dieser Therapie: Sie sei für den Menschen vollkommen schmerzfrei, heißt es. Ein Patient, mit Milliarden dieser Minirechner „geimpft“, würde vom heilenden Abwehrkampf in seinem Körper nahezu nichts merken. Lloyd Smith von der University of Wisconsin in Madison, USA, beurteilt dieses Ergebnis positiv, meint, dass sich solche Module zur Schlüsselanwendung für DNA-Computer entwickeln könnten. Jedoch schränkt Ehud Shapiro kritisch ein, sie seien „von einer klinischen Anwendung noch Jahrzehnte entfernt“. Denn was im Labor bislang mit Lungen- und Prostatakrebszellen hervorragend funktioniert, ist lange nicht geeignet für eine Anwendung beim Menschen. Langfristig hoffen die Weizmann-Forscher jedoch, diese Methode auf weitere Krebsarten ausdehnen zu können.
„Die Arbeit der Wissenschaftler um Ehud Shapiro leistet einen entscheidenden Beitrag zur Entwicklung miniaturisierter biokompatibler DNA-Computer, die Reparaturaufgaben im menschlichen Körper selbsttätig ausführen können“, urteilt Thomas Hinze, der an der Technischen Universität Dresden Biorechner und ihre Anwendungen in der Informatik erforscht. „Solche DNA-Computer besitzen ein großes Potenzial in der medizinischen Diagnostik.“ Und der Dortmunder Informatiker Udo Feldkamp bestätigt: „Shapiros Methode ist intellektuell sehr brillant und äußerst knifflig.“
Eine neue Methode entwickelten Michal Soreni und seine Kollegen vom Technion-Institut in Haifa, Israel. Sie koppelten die Eingabe-DNA-Moleküle an einen goldbeschichteten Chip. Dieser berührt bei jedem Rechenschritt nur die gerade benötigten „Programm-Moleküle“. Auf diese Weise werden die zahlreichen parallelen Rechenoperationen erst möglich. Laut Studienleiter Ehud Keinan eignet sich sein Biocomputer vor allem für komplizierte Verschlüsselungen.
Literatur über und Experten für Biorechner im deutschsprachigen Raum
- TU Dresden, Fakultät Informatik, Institut für Theoretische Informatik, Arbeitsgruppe Computing with Molecules, Dr. Monika Sturm, Dr. Thomas Hinze
- Fraunhofer Gesellschaft Biomolekularer Informationsverarbeitung BIOMIP, Schloss Birlinghoven, Sankt Augustin, offiziell: Ruhruniversität Bochum, Prof. John S. McCaskill
- Universität Dortmund, Fachbereich Informatik, Prof. Wolfgang Banzhaf, Udo Feldkamp
- Universität Leiden (NL), Prof. Rozenberg
Thomas Hinze, Monika Sturm, Rechnen mit DNA Eine Einführung in Theorie und Praxis. Oldenbourg Wissenschaftsverlag München, 316 S., 2004, ISBN 3-486-27530-5