Warum "Watson" ein Durchbruch ist
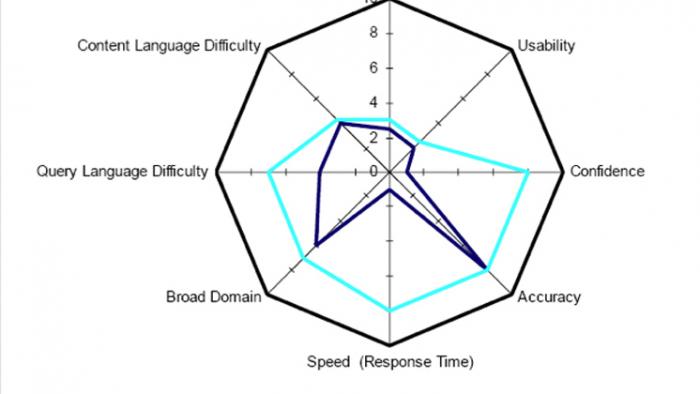
Abb. 2: Vergleich zwischen TREC und Jeopardy! entlang verschiedener Komplexitätsdimensionen. In der Mitte ist jede Dimension Null bzw. sehr klein, am Rand des Polygons ist jede Dimension groß.
Vor einem Jahr hat das von IBM entwickelte Frage-Antwort-System "Watson" in der amerikanischen Quiz-Show "Jeopardy!" die beiden besten menschlichen Spieler besiegt. Ein weiterer Meilenstein bei der Entwicklung maschineller Intelligenz
Ende 2011 habe ich mich wiederholt darüber gewundert, dass Wissenschaftler an unserer Universität nur wenig über das IBM-System namens "Watson" gehört bzw. gelesen hatten. Eigentlich kommt es nicht jeden Tag vor, dass ein Computer Menschen auf ihrem ureigenen Terrain schlagen kann, nämlich linguistisches assoziatives Schließen.1 [1]
Seitdem Alan Turing in den fünfziger Jahren einen operativen Test vorschlug, um beurteilen zu können, ob ein Computer denken kann oder nicht, hat kein Rechner den Turing-Test bestanden. Kein Wunder: im Turing-Test muss ein Computer sich mit einem Menschen per Chat-Zeile unterhalten und dabei so tun, als ob er ein Mensch wäre, ohne dass die chattende Person besser als zufällig das Gegenteil erraten kann. Auch Watson erfüllt den Turing-Test nicht. Nichtsdestotrotz haben Computer Menschen bei den verschiedensten Gesellschaftsspielen nach und nach übertroffen:
- 1979 schlug ein Computer den amtierenden Backgammon-Weltmeister.
- Seit 1986 gewinnt das Programm Maven ständig gegen Experten in Scrabble.
- 1994 wurde das Programm Chinook Weltmeister des Mensch-vs.-Maschine-Wettbewerbs in der Checkers-Variante des Damenspiels. Im Jahr 2007 wurde das Spiel dahingehend "gelöst", dass der Computer immer perfekt spielt und kein Spiel mehr verloren gehen kann.
- 1997 gewann der Parallelrechner "Deep Blue" ein Turnier gegen den amtierenden Schachweltmeister Gary Kasparov. Auf diesen Sieg eines Computers gegen einen Schachweltmeister hatten Wissenschaftler 50 Jahre lang gewartet.2 [2]
Computer sind bei kombinatorischen Spielen so gut, weil sie unendliche Geduld haben: Die Palette der ausführbaren Spielzüge (bis zu einer gewissen Tiefe) wird mit roher Gewalt im Prozessor durchgerechnet. Seit 1997, als Kasparov geschlagen wurde, sind Mikroprozessoren tausend Mal schneller geworden. Heute braucht man keinen Großrechner mehr [3], um den Schachweltmeister ins Schwitzen zu bringen.
Das Wesentliche bei unserem Thema ist jedoch, dass Quiz-Wettbewerbe eine ganz andere Art von Vergleich zwischen Mensch und Maschine darstellen. Rohe Rechenleistung und riesiges Gedächtnis sind von großem Vorteil, reichen aber für diese Aufgabe alleine nicht aus. Der Computer muss die gestellte Frage "verstehen"; er muss wissen, welche Art von Auskunft erwartet wird, und muss dann in einer Datenbank von Dokumenten nach der richtigen Antwort suchen. Die linguistische Ebene tritt sowohl bei der Erkennung der Frage als auch beim Durchsehen der Datenbasis in den Vordergrund auf. Es ist nicht wie beim Schach, bei dem das ganze Spielbrett mit nur 64 numerischen Feldern dargestellt werden kann und das Regelwerk ziemlich übersichtlich ist. Bei Frage-Antwort-Systemen haben wir eine "offene", keine "geschlossene" Welt. Alles darf gefragt werden: Nichts Menschliches, nihil humani, ist dem Computer fremd.
Was ist "Jeopardy!"?
Die Fernsehsendung "Jeopardy!" wird in verschiedenen Formaten seit 1964 in den USA ausgestrahlt. Es geht um Allgemeinbildungsfragen in allen möglichen Bereichen: Geografie, Sport, Filme, Politik, usw. Im Unterschied zu Sendungen wie "Wer wird Millionär?" müssen die Fragen direkt und ohne Multiple-Choice-Alternativen beantwortet werden. Die Frage wird außerdem sehr verklausuliert und blumig formuliert. Es ist nicht augenblicklich klar, was gefragt wird - Menschen brauchen einen Moment des Nachdenkens. Es gibt auch Fangfragen und Wortspiele.

Beim laufenden Quiz geht es darum, als erster von drei Spielern einen Summer zu aktivieren (typischerweise innerhalb von drei Sekunden), um die gestellte Frage beantworten zu dürfen. Eine richtige Antwort wird mit Preisgeld belohnt. Fehler werden allerdings mit Geldverlusten bestraft. Deswegen ist es wichtig zu wissen, wie groß das Vertrauen in eine mögliche Antwort ist. Ist der Spieler sich einer Antwort nicht sicher, kann es günstiger sein, anderen Teilnehmern den Vortritt zu überlassen. Die Fragen sind in Kategorien wie "Sport" oder "Präsidenten" unterteilt, es gibt aber auch Kategorien für Wortspiele bzw. Puzzles.
Ein paar Beispiele können illustrieren, wie schwer manchmal die Beantwortung der Fragen sein kann. Die eigentliche Fragestellung wird als Aussage formuliert, die Antwort muss als Frage gestellt werden. Diese "Umkehrung" ist bloß ein Gimmick, macht aber das Ganze nicht komplizierter, als wenn die Fragen als echte Fragen und nicht als Aussagen formuliert würden. Beispiele:
Die Sätze oben zeigen, dass die Fragen in den Formulierungen relativ "versteckt" sind. Wortfragmente wie "this" oder "they" deuten auf die Art von Antwort hin, die erwartet wird. Die Entschlüsselung der Frage kann aber sehr knifflig werden. Außerdem kann Geld in verschiedenen Stufen des Spiels gewettet werden -- deswegen muss Watson alle Spielregeln kennen und eine Wettstrategie besitzen. Diese Aspekte von Jeopardy! sind aber nebensächlich hier. Relevant ist die Frage-Antwort-Architektur des Systems.
Anfang 2008 lud das IBM Thomas-Watson-Forschungszentrum in New York zu einem Treffen zwischen Industrie und akademischer Forschung ein, um die Zukunft von Frage-Antwort-Systemen zu erörtern. Obwohl solche Systeme auf eine alte Geschichte zurückblicken können, gab es bis dahin nur mäßige Erfolge mit Anwendungen. In Mittelpunkt der Diskussion stand deshalb die Festlegung auf eine Herausforderung auf dem Bereich der Frage-Antwort-Systeme, die zu einer deutlichen Steigerung des Stands der Kunst führen könnte.
Das Beispiel des Roboterfußballs wurde ausdrücklich erwähnt: Solche Robotik-"Challenges" dienen als Labor für eine konzentrierte und zielgerichtete Kollaboration vieler Forscher. Mögliche Benchmarks wurden auch besprochen:
- der jährliche TREC-Wettbewerb (Text REtrieval Conference), bei dem 500 Fragen innerhalb einer Woche von einem Computer mit Zugriff auf einige Millionen Dokumente beantwortet werden müssen,
- Jeopardy!, wobei das Spiel in Echtzeit erfolgt, und
- "Learning by Reading", d.h. der alte Traum, den Computer Bücher lesen zu lassen, um automatisch daraus eine strukturierte Wissensdatenbank zu generieren.
Abb. 2 zeigt die Dimensionen der Komplexität der Aufgaben. Abgewogen wurden die Schwierigkeit der Fragen, die spätere Anwendbarkeit, die zum Antworten notwendige Konfidenz, Genauigkeit, Schnelligkeit, Breite der Domain, Schwierigkeit der Deutung, Schwierigkeit der verwendeten Sprache, usw. Wie Abb. 2 zeigt, muss der Computer bei Jeopardy! schnell, akkurat und mit höher Konfidenz antworten können.3 [5] Die Fragen stammen dort aus beliebigen Gebieten und die Sprache zu deuten ist schwer. Letztendlich hat IBM Jeopardy! als die nächste Herausforderung für das eigene QA-Team ausgewählt. Es wurde entschieden, dass das System ohne Internetverbindung auskommen sollte, d.h. das gesamte Watson-Weltwissen sollte im Speicher des Rechners enthalten sein.
Allerdings wurde bereits beim damaligen Treffen etwas sehr wichtig besprochen: IBM wollte pragmatisch vorgehen und war an gemeinsamen Schnittstellen und Datenformaten interessiert. D.h. es sollten verschiedene Ansätze verfolgt werden, so dass Industrie und Akademie an unterschiedlichen Modulen arbeiten könnten, die dann wie Lego-Steine zu einem Gesamtsystem "gesteckt" werden könnten. Daher die Idee, ein offenes Rahmenwerk für Frage-Antwort-Systeme zu schaffen. Dieser Ansatz war letztendlich sehr wichtig für den Erfolg des Projektes.
Die Architektur von Watson
Watson ist ein System für das Spielen von Jeopardy!: benutzt wurden 2880 Prozessorkerne, mit 14 Terabytes RAM. Die Maschine ist gewiss gewaltig, aber die Programmierung ist das wichtigste. Für die Öffentlichkeit trägt die Software den Name des IBM-Gründers. Die dazu verwendete Technologie wird von IBM jedoch DeepQA (tiefes Fragen-Antworten) genannt.
Ich hatte das Glück, neulich Dr. John Prager vom Watson-Team bei einer Tagung an der Universität Cambridge kennen zu lernen. An zwei Abenden und abschließendem Umtrunk in dem auch durch James Watson und Francis Crick berühmt gewordenen Pub "The Eagle" war Prager sehr deutlich: Obwohl sich DeepQA auf bekannte Technologien stützt und keiner für sich alleine für den Erfolg des Systems verantwortlich gemacht werden kann, spielen drei Faktoren die wesentliche Rolle. Darin bestand auch der eigentlichen Beitrag des DeepQA-Teams:
- Erstens, die Organisation des Systems rund um eine sorgfältig definierte Pipeline bei der Hypothesen sequentiell überprüft werden.
- Zweitens, die Normierung der Pipeline-Schnittstellen, wodurch viele alternative Ansätze parallel mit der Pipeline verfolgt werden können.4 [6] Hunderte von Alternativantworten und bis zu 100.000 Textfragmente und Datenbankeinträge können parallel analysiert und bewertet werden. Damit konnte das große IBM-Team an verschiedenen Baustellen gleichzeitig und ohne sich selbst zu behindern arbeiten.
- Drittens die Benutzung von Gewichtungsfunktionen, um partielle Evidenz-Werte (aus einem Ensemble von Klassifikatoren) zu einem gemeinsamen Score mit Hilfe von gelernten Gewichtungen zu verwandeln.
DeepQA ist also als Software-Pipeline strukturiert: Die sprachlich formulierte Frage durchläuft eine Reihe von Verarbeitungsstufen (siehe Abb. 3). Da beliebige Fragen gestellt werden können, startet DeepQA mit einer Analyse der Jeopardy!-Aussage, um zu bestimmen, was überhaupt gesucht wird und aus welcher Kategorie die erwartete Antwort stammt. Eine Aussage, die z.B. das Wortpaar "this person" enthält, sucht nach einer Person. Eine Frage, in der "that year" vorkommt, erkundigt sich nach einem Datum. Allerdings können die Sätze wie im obigen Beispiel über das Pariser Museum ziemlich weitschweifig gebildet werden. Ein Präprozessor und Syntaxanalyzer muss deswegen die Aussagen in Elementarsätzen herunter brechen und nach dem Hinweis für die gesuchte Antwort fahnden. In dem Fall ist der Hinweis "this art period", d.h. dies ist die "linguistische Kategorie" der zu erwarteten Antwort.
Um auf solche Anfragen reagieren zu können, studierten die DeepQA-Entwickler, die in Jeopardy! häufig verwendeten lexikalischen Kategorien und kamen auf 2.500 Arten, z.B. Städte, Personen, Filme. Bereits die häufigsten 40 dieser Kategorien decken die meisten Fragen ab. Allerdings konnte bei etwa 11% der Fragen die gesuchte Kategorie nicht ermittelt werden. In solchen Fällen ist es für den Computer im Spiel besser, ganz auf eine Antwort zu verzichten.
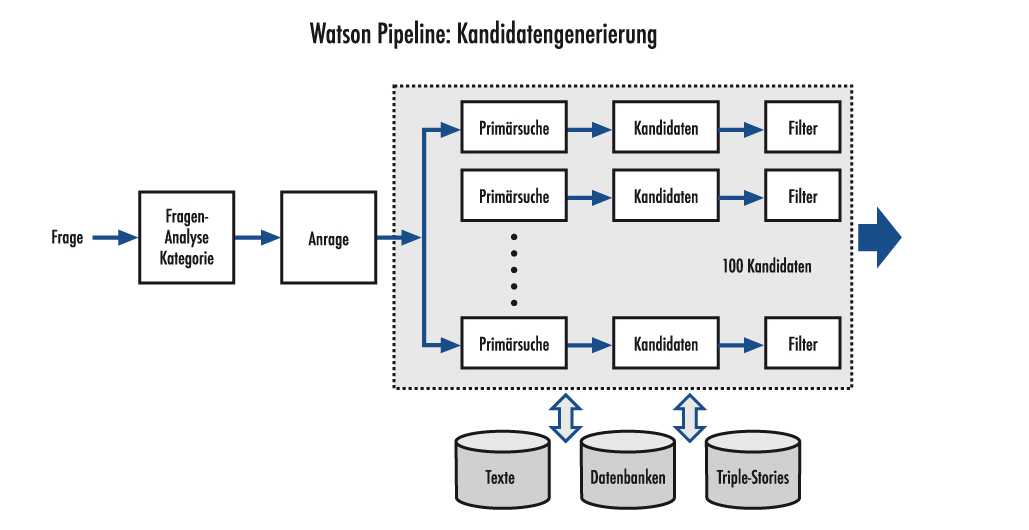
Der linguistische Präprozessor von DeepQA verwandelt die Jeopardy!-Aussage in eine Anfrage für verschiedene Arten von Hypothesengeneratoren.5 [7] Abb. 3 zeigt die Hauptidee: Die Anfrage kann z.B. Stichworte und die dazu gesuchte Kategorie enthalten. Mehrere Hypothesengeneratoren starten parallel und benutzen eine beliebige Methodik.
Man kann z.B. die Stichworte einfach in Wikipedia suchen und den Titel der Wikipedia-Seite als Antwort verwenden. Oder man schaut in strukturierten Datenbanken wie z.B. DBpedia [8]. Oder man sucht in einer Liste von amerikanischen Städten (wenn das die Kategorie ist), ob ihre Beschreibung in der Datenbank die gegebenen Stichworte enthält. Der Fantasie werden an dieser Stelle keine Grenzen gesetzt. David Ferrucci, der Leiter des Projektes, hat berichtet, dass in Watson etwa 100 verschiedene Ansätze von IBM selbst und aus der Literatur integriert wurden. Ein einfacher Filter (der z.B. die Kategorie der Hypothesen überprüft) rundet die Suche nach Kandidaten ab. Dafür können sogenannte Triple-Stores verwendet werden, die z.B. den Namen "Abraham Lincoln" mit dem Attribut "Präsident von" mit "USA" verbinden. Solche Triple-Stores können aus den Wikipedia-Tabellen und Infoboxen generiert werden und dienen manchmal sogar als Quelle für die Antwort, häufiger als Material für die Überprüfung bzw. Zurückweisen einer Hypothese. Nach der Filterung überleben etwa 100 aus 250 Hypothesen und die Pipeline arbeitet weiter an einer "tieferen" Inspektion der Kandidaten anhand von Evidenzfragmenten.
Bewertung der Hypothesen
Während der vordere Teil der DeepQA-Pipeline für die Hypothesen-Generierung verwendet wird, wird der zweite Teil der Pipelines für die Bewertung und weitere Ausdünnung der Kandidaten benutzt. Hier kommen auch verschiedene Verfahren parallel zum Einsatz. Wenn "Washington" die Hypothese bezüglich der Hauptstadt der USA ist, kann man z.B. in Wikipedia oder anderen Enzyklopädien nach dem Satz "Washington ist die Hauptstadt" suchen. Findet man den Satz, steigt unser Vertrauen an diese Hypothese.
Es werden beispielsweise auch Zeit und Raum überprüft: Wenn nach einem Philosophen aus dem 19. Jahrhundert gesucht wird, kommt Aristoteles nicht in Frage. Wenn nach einem Europäer gesucht wird, kann der Computer nicht mit Martin Luther King antworten. Bei der Überprüfung von 100 Hypothesen werden bis zu 100.000 Evidenzobjekte wie Texte, Datenbankeintragungen, Triple-Stores zur Hilfe gerufen. Am Ende scheiden die meisten Hypothesen aus und es bleiben nur einige übrig, die einer finalen Überprüfung und ein Ranking durchstehen müssen.
Die Parallelität von DeepQA kann man sich als eine Matrix vorstellen. Die Zeilen der Matrix sind die verschiedenen Hypothesen. Die Spalten der Matrix sind die Evidenzbewerter. Etwa 100 verschiedene Hypothesen werden anhand von bis zu 1000 Evidenzfragmenten oder Evidenzkriterien überprüft. Daraus ergeben sich bis zu 1000 individuelle Scores pro Hypothese, die zum sofortigen Zurückweisen oder zur Berechnung eines endgültigen Scores führen. Abb. 4 zeigt diese Idee als eine Matrix, bei der einzelne "Experten" ihr Votum für jede Hypothese abgeben.
DeepQA ist deswegen vor allem ein Software-Rahmenwerk für die Anbindung von vielen verschiedenen Verfahren und Methoden (dies nennt man in der Mustererkennung "Ensemble Methoden") aus dem Gebiet der Textretrieval. Da die Schnittstellen in der Pipeline standardisiert sind, kann ein neues Verfahren für die Hypothesengenerierung sofort getestet werden: Es kommt einfach eine neue Zeile hinzu. Man kann auch sofort ein neues Gütekriterium einbauen: Es kommt eine Spalte (und das dazugehörige Score) hinzu. Damit kann man, gegeben das Basissystem, sehr schnell und mit wenig Aufwand prüfen, ob eine neue Idee etwas zum Gesamtergebnis beitragen kann oder nicht. Die Watson-Entwickler haben z.B. speziell für Jeopardy! ein Wortspiel-Kriterium eingeführt, das in vielen Fällen sehr hilfreich war.
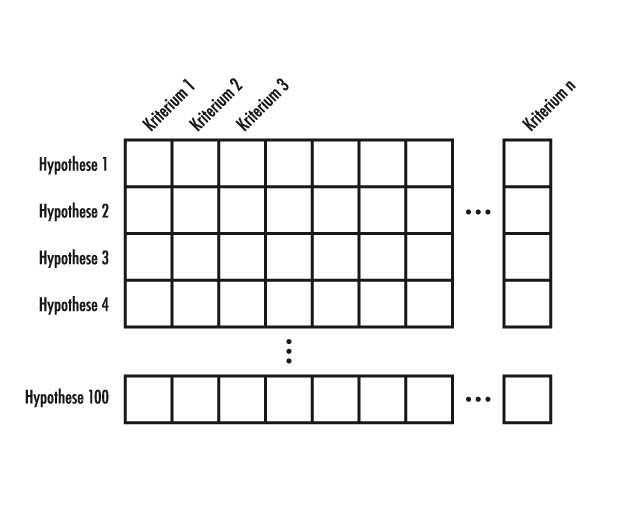
Damit stoßen wir auf ein wichtiges Prinzip bei Spielen der Art Mensch-gegen-Maschine: Wenn keine absolute Sicherheit in 100% der Fälle verlangt wird, können statistische Verfahren benutzt werden. Der Computer wird einige Fehler machen, wenn aber im Laufe des Spiels die Gewinne die Verluste ausgleichen, bleibt die Maschine im Geschäft. DeepQA kann man deswegen als ein statistisches Ensemble von Experten verstehen, die ein numerisches Votum (ein Score) für jede Hypothese abgeben.
Abb. 5 zeigt den zweiten Teil der DeepQA-Pipelines. Ähnliche Quellen wie für die Kandidatengenerierung werden verwendet, aber nicht unbedingt dieselben. Um möglichst gute Evidenzfragmente zu haben und zur Erweiterung um wichtige Quellen, wie z.B. Wikipedia, wurde eine statistische Quellen-Expansion eingebaut.6 [9] Dies bedeutet, dass man eine Textquelle nimmt (z.B. die Wikipedia-Seite über Napoleon) und diese einerseits ausdünnt, indem Textpassagen, die redundant oder nicht relevant sind löscht, aber andererseits in das Internet geht und ähnliche Quellen sucht (d.h. Texte über Napoleon). Aus den zusätzlichen Quellen werden solche Sätze entnommen, die nützliche Information enthalten. Diese werden zum vorher ausgedünnten Dokument hinzugefügt und am Ende hat man ein "Pseudo-Dokument", das wahrscheinlich für Menschen langweilig wäre (mit vielen Wiederholungen des Inhalts in verschiedenen wörtlichen Formulierungen), aber für den Computer sehr nützlich ist, da in verschiedenen Sprachvarianten das Gleiche gesagt wird. Einer der vielen Software-Bewerter wird vielleicht etwas mit einem der Fragmente anfangen und diese als Evidenz verwenden können.
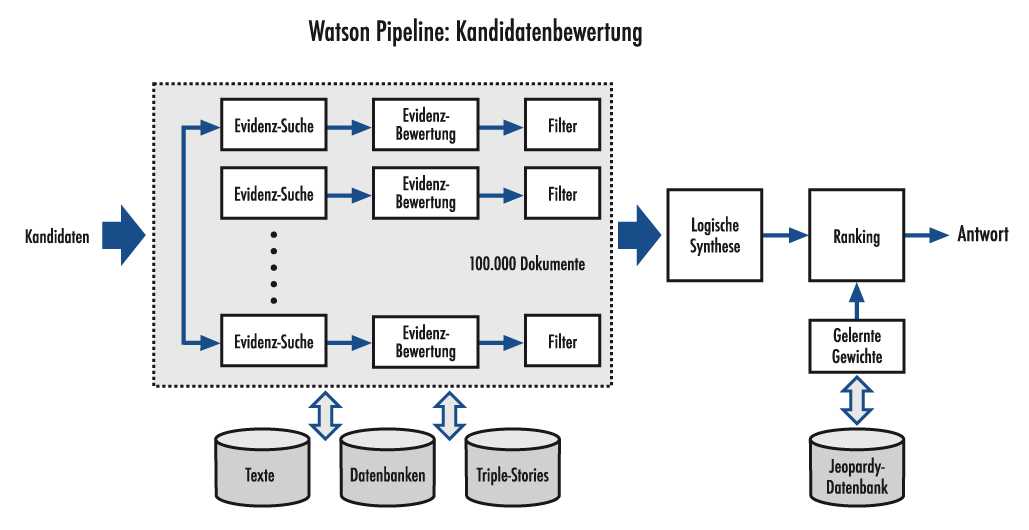
Am Ende der DeepQA-Pipelines haben wir dann die Hypothesen, die die Überprüfung überlebt haben, und einige hundert Scores. Die von den Expertenverfahren vergebenen numerischen Noten werden einfach linear kombiniert, d.h. es wird ein gewichteter Mittelwert berechnet, der dann zwischen 0 und 1 skaliert wird (dies nennt man logistische Regression). Die Gewichte für die gewichtete Summe werden anhand einer umfangreichen Datenbank von Jeopardy! Fragen, für die die Antworten bekannt sind, maschinell gelernt. So lernt das System beispielsweise wie viel Gewicht für Wortspiele oder wie viel Gewicht für die richtige geographische Nähe zu vergeben ist.
Sehr komplexe logische Überlegungen werden in Watson nicht angestellt. Das System versteht nichts von Beweisen und kann die einfachsten Schlussfolgerungen nicht bewältigen. Es werden höchstens ein paar transitive Beziehungen verwendet und Synonyme erkannt. Für die IBM-Forscher ist deswegen der nächste Schritt, Inferenzmechanismen in DeepQA einzubauen. Als neue Aufgabe sind medizinische Systeme ausgewählt worden. Watson wird in Zukunft dem Arzt über die Schulter schauen und als Berater dienen, der immer weiß, welche Nebenwirkungen zu erwarten sind oder welche Laborwerte einer Behandlung mit einem gewissen Medikament im Wege stehen.
Bevor Watson 2011 in US-Fernsehen auftrat, hat IBM das System ausführlich getestet. Es wurden die besten Jeopardy!-Spieler der letzten Jahren nach Yorktown Heights eingeladen, wo 55 Jeopardy!-Testspiele ausgetragen wurden. Watson konnte 71% der Testspiele gewinnen, wurde im Laufe des Jahres 2010 immer stärker, bis die IBM-Forscher sich sicher waren, dass Watson gegen die besten menschlichen Spieler gewinnen könnte. Da DeepQA eine Maschine ist, kann es jeden Tag nur noch besser werden: Immer bessere Quellen werden synthetisiert, jedes neue innovative Verfahren für Frage-Antwort-Systeme kann integriert werden, usw. Das ist der bleibende Beitrag des DeepQA-Teams: Eine Methodologie für den standardisierten Einbau von Teilexperten in einer Entscheidungspipeline bei Text-Retrieval-Systemen entwickelt zu haben.
Ensembles und die Mikrostruktur des Geistes
Es wird häufig die Frage gestellt, welches das beste Verfahren für die Mustererkennung sei. Eigentlich keines per se. Jeder Klassifikator kann in einem anderen Kontext von einem anderen geschlagen werden. Lineare Klassifikatoren können neuronale Netze schlagen, wenn das Problem nach linearen Trennungen verlangt. Das Beste ist eigentlich, ein gutes "Team" zu haben, d.h. eine Mischung von Klassifikatoren, die sich jeweils auf unterschiedliche Aufgaben konzentrieren können. Solche "Ensembles" sind in den letzten Jahren intensiv studiert worden. Obwohl IBM seit etwa 1997 mit kurzen Unterbrechungen an der Jeopardy!-Aufgabe gearbeitet hatte, ist es sehr interessant festzustellen, dass der echte Durchbruch erst durch die Anbindung von vielen verschiedenen Forschern aus anderen Forschungszentren und durch die Idee gelang, eine "offene" Softwarearchitektur zu erstellen. Es erweist sich, dass schwierige Aufgaben besser in Partnerschaft, als von einem einzelnen Crack zu lösen sind.
Kurioserweise ist die Natur ähnlich pragmatisch, wenn es sich um harte Aufgaben handelt. Wir wissen heute beispielsweise, dass im visuellen Kortex nicht einfach ein Abbild des Netzhautbildes projiziert wird. Die ersten Areale im visuellen Kortex projizieren zu anderen Arealen, in denen unterschiedliche Merkmale analysiert werden. Farbe wird z.B. getrennt von Bewegung verarbeitet (d.h. in unterschiedlichen Gehirnarealen), beides muss aber für die Objekterkennung und Szenenanalyse in Verbindung gebracht werden. Wenn Farberkennung durch einen Schlaganfall ausfällt, kann die Bewegungserkennung immer noch erhalten bleiben und umgekehrt. Diese große Anzahl von parallelen Prozessen, mit denen mannigfache Gehirnareale Unterschiedliches analysieren, um am Ende eine Katze zu erkennen, nannte der Hirnforscher Semir Zeki die "Mikrostruktur" der Kognition.7 [10] Die große Frage ist immer, wie das Gehirn es schafft, diese verschiedenen Verarbeitungsareale sogar zeitlich zu verknüpfen, da die Ergebnisse zu unterschiedlichen Zeitpunkten an unterschiedlichen Stellen vorliegen. Das "Bindungsproblem" bleibt deswegen für die Neurobiologie eines der spannendsten.
Heute, wenn man Watson in einem Video [11] in Aktion sieht, kann man nur noch Gänsehaut kriegen. Wir wissen: da drin ist keine Intelligenz - Watson kann nicht mal die einfachsten Inferenzaufgaben lösen. Watsons Superhirn basiert auf Gigabytes von textuellen Quellen, aber wir projizieren unsere unbewusste Interpretation in die Maschine hinein. Immerhin hat das System die besten Spieler bei Jeopardy! geschlagen und es spukt ein wenig von der Mikrostruktur unseres eigenes Geistes in seiner parallelen Architektur aus vielen Teilexperten.
URL dieses Artikels:
https://www.heise.de/-3393439
Links in diesem Artikel:
[1] https://www.heise.de/tp/features/Warum-Watson-ein-Durchbruch-ist-3393439.html?view=fussnoten#f_1
[2] https://www.heise.de/tp/features/Warum-Watson-ein-Durchbruch-ist-3393439.html?view=fussnoten#f_2
[3] http://www.spiegel.de/netzwelt/tech/0,1518,452429,00.html
[4] http://www-03.ibm.com/innovation/us/watson/what-is-watson/the-face-of-watson.html
[5] https://www.heise.de/tp/features/Warum-Watson-ein-Durchbruch-ist-3393439.html?view=fussnoten#f_3
[6] https://www.heise.de/tp/features/Warum-Watson-ein-Durchbruch-ist-3393439.html?view=fussnoten#f_4
[7] https://www.heise.de/tp/features/Warum-Watson-ein-Durchbruch-ist-3393439.html?view=fussnoten#f_5
[8] http://de.dbpedia.org/
[9] https://www.heise.de/tp/features/Warum-Watson-ein-Durchbruch-ist-3393439.html?view=fussnoten#f_6
[10] https://www.heise.de/tp/features/Warum-Watson-ein-Durchbruch-ist-3393439.html?view=fussnoten#f_7
[11] http://www.youtube.com/watch?v=o6oS64Bpx0g
Copyright © 2012 Heise Medien