Jagd auf die "Kopfjäger" im Internet
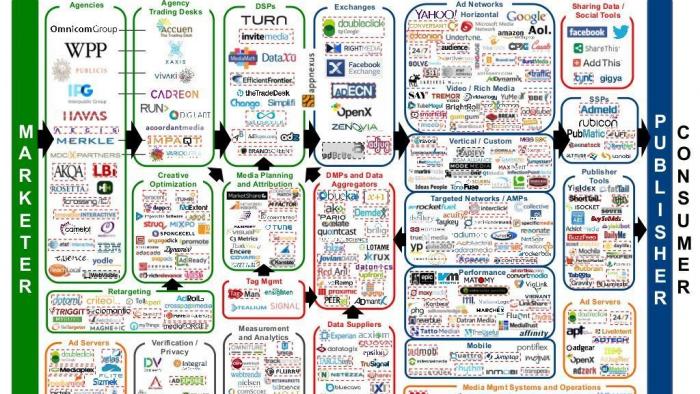
Abb. 1. Die sogenannte "LUMAscape", eine Darstellung des wirren Ökosystems von Werbeagenturen, Maklern und Informationsanbietern im Internet.
Transparenz und Schutz der Privatsphäre im Internet
Vor kurzem fand an der Universität Princeton die Web Privacy and Transparency Conference statt - eine Tagung über den Schutz der Privatsphäre. Diskutiert wurden die immer ausgefeilteren Methoden, die von Drittanbietern für das Verfolgen und die Modellierung der Interessen und Vorlieben von Internetbenutzern entwickelt werden, sowie mögliche Abwehrmechanismen.
Arvind Narayanan, Informatik-Professor am Center for Information Technology Policy der Universität Princeton, hat sich im Rahmen seines Transparenzprojekts für das Internet den Schutz der Privatsphäre der Benutzer auf die Fahne geschrieben. Er jagt die Jäger, d.h. die Dutzenden von Firmen, die heute Benutzeridentifizierungsdienste betreiben: Bevor eine Anzeige im Webbrowser des Nutzers erscheint, geben solche Anbieter die Identität bzw. die wahrscheinlichen Präferenzen des Benutzers gegen Entgelt preis, so dass die Werbung personalisiert werden kann.
Das ist so wie bei Amazon: Hat man bereits einige Bücher gekauft, schlägt Amazon selbst neue Einkäufe vor, die zu den vorherigen Büchern thematisch oder stilistisch passen. In dem Fall ist nichts zu beanstanden. Allerdings verfolgen die Drittanbieter von Identitätsdaten die Benutzer über unterschiedliche Webseiten sowie über alle Grenzen hinweg, und verknüpfen das Verhalten des Benutzers in Amazon mit dem Verhalten z.B. bei Ebay, Facebook und Twitter. Das Ergebnis ist eine komplette Röntgenaufnahme des Benutzers, womit er oder sie angreifbarer für maßgeschneiderte Werbung wird. Die Internetbenutzer werden von solchen "Kopfjägern" in Schubladen gesteckt, manchmal in die korrekte - aber oft auch in die falsche. Man weiß nicht, was irritierender ist.
Bei der von ihm organisierten "Web Privacy and Transparency Conference" am 24. Oktober hat Narayan Abb. 1 gezeigt, eine bekannte Darstellung der vielen Firmen bzw. Makler, die zwischen Informationen in Webbrowsern und den Konsumenten der Information sitzen. Wenn man heute z.B. eine Seite der New York Times lädt, hängen sich sofort verschiedene Werbefirmen an, die Anzeigen im Sichtfeld des Kunden platzieren. Während bei einem Magazin die Werbung eine mögliche, gut bekannte Leserschaft anspricht, z.B. Bieranzeigen bei Sportseiten, benutzen heutige Informationsanbieter eine "algorithmische Modellierung" des Kunden in Echtzeit. Viele der Unternehmen in Abb. 1 schauen den Benutzern über die Schulter (mit legalen, aber auch mit illegalen Mitteln), korrelieren das Verhalten von Millionen von Personen und verkaufen ihre Erkenntnisse an die Werbefirmen.
Während Cookies (alle Arten davon, sogar gelöschte und rekonstruierte Cookies) die traditionelle Art der Benutzerverfolgung darstellen und viele Firmen sich auf das Lesen der Cookies von anderen Anbietern spezialisiert haben, gibt es heute effektivere Methoden einen Benutzer unter Millionen eindeutig zu identifizieren. Dazu zählt das sogenannte Browser Fingerprinting, eine Technik über die bereits bei heise.de berichtet worden ist.
Wenn eine Webseite geladen wird, kann die Konfiguration des Browsers gelesen werden, darunter die Anzahl und Art der Plug-Ins, die Fonts, die der Browser zur Verfügung stellt, und sogar die Größe des Bildschirms. Wie das Projekt Panopticlick der Electronic Frontier Foundation belegt hat, kann über solche einfachen Tests ein Computer wiedererkannt werden. Es ist dann möglich, einen Kunden über viele besuchte Seiten zu verfolgen. Die Tracking-Firma braucht nur für ausreichend viele Webseiten zu arbeiten und kann die damit gewonnenen Daten verknüpfen und auswerten.
Für meinen Laptop stellte Panopticlick fest: "Der Fingerabdruck ihres Browsers scheint eindeutig bei den 4,643,941, die wir bis jetzt getestet haben... Wir schätzen dass ihr Browser-Fingerabdruck 22.15 Bits an Identifizierungsinformation trägt." Natürlich kann man sich davor schützen, aber dafür muss man sich sehr gut mit den Browsereinstellungen auskennen - was natürlich die meisten Benutzer nicht tun.
Ein noch tückischerer Angriff erfolgt über die Darstellung von unsichtbaren Texten. Ein Text mit allen Buchstaben des Alphabets wird in einem (für den Nutzer nicht sichtbaren) Canvas-Element dargestellt und die entsprechenden Pixel werden wieder analysiert. Es stellt sich heraus, dass sich für jeden Benutzer (durch die unterschiedlichen Computer, Betriebssysteme, Grafikarten und Bildschirme) leichte Unterschiede in der Pixeldarstellung ergeben. Diese Unterschiede erlauben dann über das sogenannte Canvas Fingerprinting die Identifizierung des Benutzers über verschiedene Webseiten hinweg.1 Bereits Anfang des Jahres benutzten 5% der am meisten benutzen Webseiten ein solches Benutzeridentifizierungsverfahren. Besorgniserregend ist, dass sobald ein neuer Angriff erdacht worden ist, dieser sich sehr schnell über die Werbemakler verbreitet.
Manipulation der Filterblase
Jonathan Mayer von der Stanford University hat bei der Konferenz etwas vorgestellt, das als eine Art Parasit die dem Benutzer angebotenen Information manipulieren kann. Dazu wird in einer Webseite wiederum Code eingebaut, die in einem unsichtbaren Fenster YouTube-Videos aufruft. Während der Benutzer sich eine Webseite mit irgendwelchen Informationen anschaut, laufen im Hintergrund nacheinander mehrere Videos (man braucht sie jeweils nur kurz anzuspielen). Wenn anschließend der Benutzer zu YouTube wechselt, hat ihn YouTube bereits kategorisiert und bietet Videos an, die ähnlich zu den gespielten, aber nicht gesehenen Videos sind.
Man lenkt damit den Benutzer über YouTube zu bestimmten Informationen, die Werbung oder politische Botschaften enthalten können. Diese Form der Manipulation schlägt dann doppelt zur Buche: einerseits, weil das Laden von Webseiten verlangsamt wird, da Ressourcen konsumiert werden, und andererseits, weil die "Filterblase" um den Benutzer verstärkt werden kann.
Die Filterblase, war eines der meist diskutierten Themen bei der Konferenz.2 Dabei handelt es sich um eine neue Erscheinung, die mit der eigentümlichen Beschaffenheit des Internets zu tun hat. Soziale Netze kann man sich beispielsweise zunächst einmal als einen Freiraum bzw. Vakuum vorstellen, in dem sich Benutzer mit denselben Affinitäten langsam bündeln, so dass sich später nur noch die Information und die Meinungen der Gleichgesinnten durchdringen. Man hat dann den Eindruck, dass nur diese Information stimmt und die eigenen Vorurteile werden noch verstärkt. Da eine Auseinandersetzung mit der Realität fehlt, weil viele Personen sich nur noch virtuell begegnen, tendieren die Meinungen schnell in extreme Richtungen.
Die Informationsblase um die Benutzer polarisiert die Gesellschaft. Sherry Turkle hat in ihren Büchern viele Beispiele von Personen gegeben, die ihre Sozialisierung nur noch über das Internet ausleben, und zeigt, wie problematisch ihre Integration in echten Lebensgemeinschaften sein kann.3
Aber es gibt Menschen, die sich gegen das Tracking und Filterblasen wehren, soch auch Julia Angwin, die bei der Konferenz den Hauptvortrag gehalten hat. Sie hat beschlossen, ihre Daten nicht weiterhin Drittanbietern von Identifizierungen preiszugeben. Ihre Bemühungen wurden in dem Buch "Dragnet Nation" dokumentiert.4 Sie musste praktisch mit allen traditionellen und bekannten Plattformen brechen. Sie ist aus Google, Facebook und Twitter ausgetreten. Ihr E-Mailkonto hat sie bei einem Anbieter eingerichtet, der keine Werbung platziert und keine E-Mail-Analyse betreibt, wie z.B. Google es macht. Dafür musste sie aber natürlich etwas Geld zahlen. Ihre Suchanfragen macht sie über eine Suchmaschine, die keine Werbung verbreitet. Am Ende musste sie feststellen, dass der Verzicht auf alle Gratisangebote bei einem normalen Internetnutzer mit etwa 2.500 US-Dollar im Jahr zu Buche schlägt - wenn man nicht völlig auf das Internet verzichten will. Und trotzdem hat sie das Ziel nicht ganz erreicht: Ihr Handy verrät ihre täglichen Bewegungen. Auf Mobiltelefonie wollte sie nicht verzichten.
Schutz der Privatsphäre
Was also tun? Das letzte Drittel der Princeton-Konferenz widmete sich diesem Thema.
Es gibt auch nette Kapitalisten, die nicht unbedingt an dem Tracking der Internetbenutzer teilnehmen wollen. Manche davon sind im Council of Better Business Bureaus organisiert und versuchen, das eigene Verhalten zu drosseln und selbst so genannte "best practices" zu implementieren. Es ist auch manchmal fraglich, was der eigentliche Gewinn bei der Verfolgung der Benutzer sein soll. Wenn sich bei einer Webseite der Inhalt des informativen Teils um E-Gitarren dreht, kann dort eine Anzeige für E Gitarren platziert werden. Es ist nicht notwendig, den Benutzer zu modellieren oder zu verfolgen. Wenn er oder sie über dieses Thema liest, kann davon ausgegangen werden, dass ein prinzipielles Interesse für solche Instrumente besteht.
"Self enforcement" reicht aber offensichtlich nicht aus. Es ist wie beim Drogenkonsum. Maßnahmen gegen die Produzenten von Drogen wirken nur kurzfristig, solange die Massennachfrage nach Drogen da ist. Wenn die Kunden nicht in die Entziehungsklinik geschickt werden, wird immer jemand in die Fußstapfen der Anbieter treten. Wenn die Nachfrage nach algorithmischer Modellierung - oder gar der kompletten Identifizierung des Benutzers mit Name und Adresse - besteht, wird es immer Drittanbieter von solchen Informationen geben.
Die geballte Kompetenz der Konferenzteilnehmer stieß an dieser Stelle auf eine unsichtbare Mauer. Wie kann man gesetzlich solche Eingriffe in die Privatsphäre der Internetbenutzer verbieten? Welche Firewalls kann man auch durch das Design der Internetbrowser und Computer einrichten, so dass man wie früher anonym im Internet surfen könnte? Hier gab es mehr Fragen als Antworten. Aber die Organisatoren der Konferenz, allen voran Narayan und Ed Felten, wollen durch ihre Projekte zunächst einmal ein öffentliches Bewusstsein für das Problem erzeugen, ähnlich wie beim Crowdsourcing-Projekt Lightbeam von Mozilla (Abb. 2). Sie wollen den Suchstrahl auf die Verfolger umdrehen, so dass sogar naive Benutzer merken, wie sie dauernd ausspioniert werden. Wie Julia Angwin sagte: Der Benutzer selbst ist das Produkt, das von Hand zu Hand digital nachgereicht wird.5
Fußnoten
[1] Herbert Braun, "Fingerabdrucke auf der Leinwand", c't, 18/14, 8.8.2014, S.36.
[2] Eli Pariser, The Filter Bubble: How the New Personalized Web Is Changing What We Read and How We Think, Penguin Books,2012.
[3] Sherry Turkle, Alone Together: Why We Expect More from Technology and Less from Each Other, Basic Books, 2011.
[4] Julia Angwin, Dragnet Nation, Times Books, 2014.
[5] Lori Andrews, "Facebook Is Using You", New York Times, February 4, 2012