Das Berechnen des Unberechenbaren
Sind Quanten- oder DNA-Computer Alternativen zum Modell der Turingmaschine
Im Alltagsleben ist die Rede gang und gäbe, eine "Berechnung" auszuführen. Wir können beispielsweise informell über den Ausgleich eines Bankkontos, über das Berechnen des Benzinverbrauchs pro Kilometer für ein Auto oder über den Umtausch von US-Dollar in japanische Yen sprechen. All das erfordert die Verarbeitung von Zahlen auf eine bestimmte Weise, um das erwünschte Ergebnis zu erzielen. Das Verfahren, mit dem wir Zahlen verarbeiten, ist ein Beispiel für das, was wir formaler als Algorithmus bezeichnen. Für die Theoretiker stellt sich das Problem, wie man dieses sehr allgemeine, aber informelle Verständnis einer Rechenoperation in eine genaue, formale mathematische Struktur überträgt, in der wir wirklich etwas über die Eigenschaften von Algorithmen beweisen können.
Das Reale und das Berechenbare
Ein solches formales mathematisches System der Berechnung wie die Turingmaschine nennt man technisch ein Modell des Rechenprozesses. Weil diese Verwendung des Begriffs von einem "Modell" als einer Art der formalen Interpretation des Informellen sich ein wenig von dem Verständnis eines Modells in der Alltagssprache unterscheidet, gebe ich hier ein Beispiel dafür, was ich darunter verstehe.
Gehen wir von zwei Mengen von Elementen aus, die wir V und B nennen. Für den Augenblick sagen wir nichts über die Struktur dieser Mengen. Sie sind reine abstrakte Objekte. Nehmen wir jetzt an, daß diese zwei Mengen die folgenden Postulate erfüllen:
- Beliebige zwei Elemente von V sind in genau einem Element von E enthalten.
- Kein Element von V ist in mehr als zwei Elementen von E enthalten.
- Die Elemente von V sind nicht alle in einem einzigen Element von enthalten.
- Beliebige zwei Elemente von E enthalten genau ein Element von V.
- Kein Element von E enthält mehr als zwei Elemente von V.
Auf den ersten Blick sieht das eher wie eine abstrakte, starre und im Grunde uninteressante Reihe von Annahmen aus. Trotzdem ist es möglich, die herkömmlichen Mittel der logischen Beweisführung einzusetzen, um die unterschiedlichen Eigenschaften der Mengen V und E aus diesen Postulaten zu beweisen. Beispielsweise läßt sich unmittelbar beweisen, daß die Menge V genau drei Elemente enthält. Ganz entscheidend ist zu verstehen, ob eine gegebene Menge von Axiomen wie die oben angegebenen Annahmen 1-5 konsistent sind, was bedeutet, daß sie niemals zu einander widersprechenden Theoremen führen können. Ein Modell für die Postulate 1-5 hilft bei der Beantwortung dieser Frage.
Nehmen wir an, V sei die Menge der Punkte, die die Scheitelpunkte eines Dreiecks bilden, und betrachten wir die Elemente von E als die Geraden, aus denen sich die Kanten des Dreiecks ergeben. Überdies deuten wir den Satz "Ein Element von V ist in einem Element von E enthalten" so, daß ein Punkt, der ein Scheitelpunkt des Dreiecks ist, auf einer Geraden liegt, die eine Kante des Dreiecks ist. Mit diesen Interpretationen läßt sich jedes der fünf obigen Postulate in eine wahre Aussage über Dreiecke übersetzen. Beispielsweise behauptet das erste Postulat einfach, daß zwei beliebige Punkte, die Scheitelpunkte des Dreiecks sind, auf genau einer Geraden liegen, die eine Kante ist. Auf diese Weise lassen sich die Postulate als konsistent betrachten. Eine geometrische Darstellung von dieser Verwendung eines Dreiecks als einem Modell für die Postulate 1-5 wird in der Abbildung 1 gezeigt.

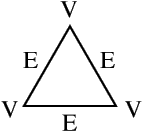
Genauso wie ein Dreieck die obigen abstrakten Postulate modelliert, dient die Turingmaschine als ein Modell für das, was wir in formalen mathematischen Begriffen als "Berechnung" verstehen. Und dieses Modell schreibt genau vor, was berechenbar ist und was nicht. Aber es gibt weitere Modelle der Berechnung, die in ihrer Form ganz anders als das Modell der Turingmaschine sind. Diese Alternativen legen wiederum ihre eigenen Mengen berechenbarer Quantitäten fest. Das Problem ist dabei, ob eines dieser Modelle zu einer Menge berechenbarer Quantitäten führt, die größer ist als diejenige, die sich mit dem Modell der Turingmaschine erzielen läßt. Gegenwärtig weiß das niemand wirklich. Aber als Spekulation verstanden ist es sinnvoll, sich zu überlegen, wie einige dieser andersartigen Modelle aussehen.
Ein großer Teil der Berechnungsprobleme, denen Wissenschaftler begegnen, werden in reellen, nicht in ganzen Zahlen ausgedrückt, beispielsweise beim Lösen einer Differentialgleichung oder beim Ausrechnen der Inversion einer Zahlenmatrix. Das Turingmaschinen-Modell der Berechnung ist nicht sehr geeignet, uns Informationen über derartige Berechnungsprozesse zu geben, da es durch binäre Reihen von ganzen Inputs und Outputs definiert wird. Man kann zwar mit diesem Aufbau mit reellen Zahlen zurechtkommen, aber das ist ziemlich mühsam und erfordert einiges an technischer Raffinesse, die das Problem der Berechenbarkeit ebensosehr verdunkeln wie erhellen.
Die BBS-Maschine
Vor einigen Jahren begann sich der bekannte Mathematiker Steven Smale aus Berkeley für diese Frage zu interessieren. Als Teil seines Unternehmens, die theoretische Grundlage der Berechnung von Dingen wie reellen und komplexen Zahlen, knöpfte sich Smale Kollegen in den Gängen und in der Cafeteria vor und fragte sie: Was verstehst du unter einem Algorithmus? Eine Antwort lautete: ein Fortranprogramm. Zusammen mit seinem mathematischen Kollegen Michael Shub und dem Computerwissenschaftler Leonore Blum überführte Smale diese Vorstellung eines Fortranprogrammes als einem Algorithmus in ein neues Modell der Berechnung, das leicht mit Berechnungen zurechtkommt, die mit ganzen und mit reellen Zahlen durchgeführt werden. Dieses Modell wird manchmal eine Flußdiagramm-Maschine oder, einfacher, nach den Initialen ihrer Erfinder, eine BBS-Maschine genannt.
Abstrakt gesehen ist eine BBS-Maschine eine begrenzte Menge an durch Bogen verknüpfte Knoten, die nur in einer einzigen Richtung durchschritten werden können. Technisch handelt es sich um einen finiten gerichteten Graphen. Diese Knoten treten in fünf unterschiedlichen Formen auf: Input, Output, Berechnung, Verzweigung und Zugriff auf den Speicher. Um zu erkennen, wie eine bestimmte BBS-Maschine aussieht, ziehen wir Newtons Methode heran, um die Quadratwurzel einer Zahl, z.B. von 2, zu finden.
Angenommen sei, daß wir von der Gleichung x<FONT SIZE=-1>2 - 2= 0 ausgehen. Wir wollen eine Wurzel dieser Gleichung finden, d.h. eine reelle Zahl x*, so daß x*<FONT SIZE=-1>2 = 2. Vor mehr als zwei Jahrhunderten entdeckte Newton ein Verfahren, um sich einer solchen Wurzel erfolgreich anzunähern. Er verwendete das Annäherungsschema
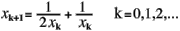
Wenn wir eine reelle Zahl finden wollen, die sich an die Wurzel aus 2 mit einer Genauigkeit von E annähert, dann beginnen wir damit, eine Ausgangszahl x<FONT SIZE=-1>0 zu schätzen. Newtons Schema läßt sich dann benutzen, um die Annäherungen x<FONT SIZE=-1>1, x<FONT SIZE=-1>2 und so weiter zu erzeugen, bis wir zu einer Zahl x kommen, so daß ||x<IMG WIDTH=3 HEIGHT=1 SRC=../../../icons/r_xxx.gif><FONT SIZE=-1>2-2||<E.
Newtons Methode zum Auffinden der Wurzel einer Gleichung ist ein Beispiel für einen Algorithmus, für ein geistloses, mechanisches Verfahren, das man von einem gegebenen Input (der Ausgangszahl x<FONT SIZE=-1>0) zu einem erwünschten Output (der Zahl x, so daß x<FONT SIZE=-1>2 - 2 nicht größer als die angegebene Genauigkeit E ist) Schritt für Schritt befolgt. Die in der Abbildung 2 dargestellte BBS-Maschine formalisiert die Schritte dieses Verfahrens.
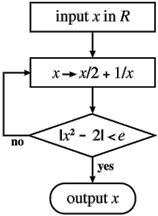
Das Diagramm in der Abbildung 2 muß mathematisch so formalisiert werden, daß es ein Modell zur Berechnung der Quadratzahl aus 2 ist. Und die allgemeine Idee zielt auf eine allgemeinere BBS-Maschine zur Berechnung der Wurzel jeder Gleichung f(x)=0, in der x seine Werte in jederZahlenfolge annimmt, gleich ob es sich um reelle und komplexe oder um ganze Zahlen handelt. Natürlich muß man sehen, daß dies ein theoretisches Modell der Berechnung ist, dessen Umsetzung in wirkliche Hardware von der Möglichkeit von dieser abhängt, perfekte, d.h. fehlerfreie arithmetische Operationen im entsprechenden Zahlenfeld auszuführen. Das bedeutet im obigen Beispiel der Berechnung der Quadratwurzel aus 2 mit den reellen Zahlen, daß die von Newtons Verfahren erforderten Additionen und Subtraktionen ohne Abrundungsfehler ausgeführt werden müssen, was mit den vorhandenen digitalen Computern unmöglich ist, die nur über eine festgelegte Wortlänge verfügen. Aber das heißt nicht, daß es notwendigerweise unmöglich ist, solche "Maschinen für reelle Zahlen" herzustellen. Manche sind der Meinung, daß analoge Computer gebaut werden können, um genau solche Rechenvorgänge auszuführen.
Eines der primären Motive zum Bau der BBS-Maschine ist, die Leistung der mathematischen Analyse für Probleme, die durch reelle oder komplexe Zahlen definiert werden, zur Verfügung zu haben, und gleichzeitig die gut entwickelte Theorie der Turing-Berechenbarkeit von Integralen benutzen zu können.
Eines der ersten großen Ergebnisse beim Gebrauch der Maschine durch BBS lag im Bereich der Entscheidbarkeit. Geht man von einer Teilmenge S von Eingaben aus, dann sagt man, daß eine Maschine S aufgrund jeder möglichen Eingabe x sich für die Ausgabe JA entscheidet, wenn x ein Teil von S ist, und für NEIN, wenn x nicht der Teilmenge Sangehört. Dieses Konzept wurde von BBS verwendet, um sich der Frage zuzuwenden, ob ein gegebener Ausgangswert bei der Methode Newtons zu einer Menge von Näherungen für x<FONT SIZE=-1>1, x<FONT SIZE=-1>2 ... führen würde, die zu einer wirklichen Wurzel einer Gleichung verschmelzen. Im Besonderen entdeckten BBS, daß die Gleichung ein Polynom p(z) mit komplexen Koeffizienten ist und daß es keine BBS-Maschine gibt, die entscheiden kann, ob ein gegebener Ausgangswert z<FONT SIZE=-1>0 mit einer Zahl z zusammengeht, so daß p(z) = 0, wenn das Polynom mindestens drei verschiedene komplexe Wurzeln besitzt.
Mit der BBS-Maschine ist es möglich, die Idee der NP-Vollständigkeit auf Probleme zu erweitern, die reale und komplexe Zahlen enthalten. Ein bekanntes NP-Vollständigkeitsproblem für die ganzen Zahlen ist beispielsweise Hilberts 10. Problem, das nach einem allgemeinen Verfahren (lies: einem Algorithmus) sucht, das sagt, wenn eine gegebene polynomische Gleichung mit ganzzahligen Koeffizienten eine Lösung (lies: eine Wurzel) in ganzen Zahlen besitzt. Das berühmte, unlängst von Andrew Wiles gelöste Fermatsche Problem ist genau eine solche Frage für die Gleichung x<FONT SIZE=-1>n + y<FONT SIZE=-1>n - z<FONT SIZE=-1>n= 0, wobei n eine ganze Zahl größer als 2 ist. Hier ist die Frage, ob es für ein jedes derartiges n ganzzahlige x, y und z gibt, die diese Gleichung lösen. Wiles Beweis zeigt, daß dies nicht so ist. Das ist ein Ergebnis, das die berühmte Vermutung bestätigt, die Fermat vor über zwei Jahrhunderten traf.
Eine analoge Frage, die reale anstatt ganze Zahlen beinhaltet, ist: Gibt es für ein Polynom p(x) des vierten Grades mit realen Koeffizienten eine reale Wurzel der Gleichung? Gibt es also ein Entscheidungsverfahren, ob eine reale Zahl x existiert, so daß p(x) = 0? BBS konnten zeigen, daß dieses Problem genau auf dieselbe Weise NP-vollständig ist, wie Hilberts 10. Problem NP-vollständig für ganze Zahlen ist. Viele weitere Ergebnisse in dieser Richtung werden in den Literaturangaben berichtet. Entscheidend dabei ist, was man nicht vergessen sollte, daß die BBS-Maschine zeigt, daß Turings Definitionsweise dessen, was wir unter einer Berechnung verstehen, nur eine von vielen Weisen ist, wie man dieses Konzept formalisieren kann, auch wenn sie mathematisch und zur physikalischen Implementierung in wirklicher Hardware sehr geeignet ist. Aber es gibt Alternativen,beispielsweise ein auf Prozessen basierendes Modell, die in jeder Zelle eines Lebewesens ablaufen: ein sogenannter DNA-Computer.
DNA-Computer
Leonard Adleman von der University of Southern California veröffentlichte 1994 einen Artikel in Science, der eine Revolution in unserem Verständnis der Berechnung auslöste. In seiner Forschung brachte Adleman DNA-Stränge dazu, sich genau in der richtigen Weise zu verbinden, um ein "schweres" Berechnungsproblem zu lösen, das sehr eng mit dem bekannten Problem der Geschäftsreisenden ist. Das als gerichtetes Hamilton Wegproblem (DHPP) bezeichnete Puzzle beinhaltet die Suche nach einem Weg durch eine Gruppe von Städten, die auf verschiedene Weise durch Einbahnstraßen verbunden sind. Ein Hamilton-Weg in einem solchen Netzwerk von Städten führt im Netzwerk einmal und nur einmal durch jede Stadt. Das DHPP fragt, ob es in einem Netzwerk einen solchen Weg gibt, oder es erzeugt einen solchen Weg, falls es einen gibt.
Das DHPP ist ein Beispiel für ein NP-vollständiges Problem. Man kann leicht jeden einzelnen Weg überprüfen, um zu sehen, ob er wirklich ein Hamilton-Weg ist, aber es ist sehr schwierig, einen solchen Weg erst einmal zu finden. Die Schwierigkeit besteht natürlich darin, daß alle bekannten Algorithmen zum Finden eines Weges, der durch eine Stadt einmal und nur einmal führt, eine äußerst große Komplexität aufweisen, die exponentiell im Verhältnis anwächst. Es gibt also Netzwerke von Städten mittlerer Größe, d.h. N Städte, die eine exponentiell in N zunehmende Rechenzeit erfordern. das wäre natürlich überhaupt keine Schwierigkeit, wenn wir auf einmal alle möglichen Wege überprüfen könnten. Genau das ermöglichte der "DNA-Computer" Adlemen. Ich lege dar, wie er die physikalischen Eigenschaften der DNA nutzte, um diese Herkulesarbeit zu bewältigen.
Mit der DNA verschlüsselt die Natur riesige Informationsmengen in einer sehr kompakten Weise. Ein einziger DNA-Strang enthält beispielsweise die gesamte Information, um einen Elefanten, einen Menschen oder ein Pterodactyl zu erzeugen. Adleman setzte diese Kapazität zur Informationsspeicherung ein, um die Städte und Straßen eines Netzwerks sowie die Wege durch den Graphen in DNA-Strängen zu codieren. Dann richtete er einen Experimentaufbau ein, mit dem er die vier Schritte im folgenden Algorithmus ausführen konnte:
- Erzeuge eine Vielzahl von Wegen durch das Netzwerk.
- Entferne alle Wege außer jenen, die beim ausgewählten Startpunkt beginnen und in der festgelegten Zielstadt enden.
- Entferne alle Wege außer jenen, die genau N Städte besuchen, wobei N als die Zahl der Städte angegeben wurde, die auf einem Hamilton-Weg besucht werden sollen.
- Entferne alle Städte außer jenen, die zu jeder Stadt führen.
Alle DNA-Stränge, die nach diesen Schritten in der "Suppe" verbleiben, müssen den Hamiltonschen Pfaden durch das Netzwerk der Städte entsprechen.
Das Problem, das Adleman in Wirklich löste, war das Auffinden eines bestimmten Pfades durch das Netzwerke der Städte. Man nehme beispielsweise die vier Städte New York, Paris, Wien und Tokyo. Nonstop-Flüge gibt es nur von New York nach Paris, von Paris nach Tokyo und von Wien nach Tokyo. Man könnte also die Frage stellen, auf welcher Strecke ein Reisender alle Städte besuchen kann, wenn nur drei Flüge macht. In diesem Fall ist die Antwort offensichtlich: Fliege von New York nach Paris, dann nach Wien und schließlich nach Tokyo. Aber wenn das Problem alle großen Städte der Welt und alle Verbindungsflüge beinhaltet, dann würde die Anzahl der möglichen Wege astronomisch groß werden.
Adleman löste ein Sieben-Städte-Proble dieser Art durch die Codierung der Einzelheiten in DNA-Stränge. Die Doppelhelix der DNA besteht aus zwei komplemantären Strängen der vier DNA-Säuren, die man A, T, G und C nennt. Die Aminosäure A ist das Komplement von T, d.h. sie kann nur mit T verbunden sein. Auf dieselbe Weise ist G das Komplement von C. Ein Strang des DNA-Moleküls ist daher ein komplementäres Spiegelbild des anderen. Adleman wählte zufällige einzelne Strangcodes aus, um jede Stadt zu repräsentieren, beispielsweise ATGCGA für New York, TGATCC für Paris und GCTTAG für Wien. Dann können die jeden Flug repräsentierenden Stränge durch die letzten drei Codebuchstaben der Abflugstadt und die ersten drei Buchstaben der Zielstädte definiert werden. Folglich würde ein Flug von New York nach Paris im obigen Vier-Städte-Beispiel als CGATGA codiert werden.
Mit der Gentechnik ist es möglich, bestimmte DNA-Stränge nach Wunsch herzustellen. Adleman vermischte in seiner Testschale die komplentären DNA-Stränge, die Städte, beispielsweise ACTAGG fürParis, codieren, mit den Flugstreckensträngen. Da sie sich zu Doppel-Helix-Strängen verbinden, fungierten die Flugstreckenstränge als komplementäre Brücken, um die Stadtstränge zusammen zu halten. Es bildeten sich Moleküle für alle möglichen Flugkombinationen, aber es war unter der Voraussetzung, daß Milliaren von Molekülen reagierten, fast sicher, daß sich in der Ergebnislösung ein Molekül befinden würde, das den richtigen Flugweg repräsentiert.
Das Problem bestand in der Identifizierung des Moleküls, das eine Lösung für das Problem darstellte, unter all den zigmillionen anderen Molekülen, die in der DNA-Suppe herumschwebten. Dieses magische Molekül hat die Eigenschaft, daß es sich über die Länge aller Stadtcodes hinweg erstreckt, beginnend mit der Ausgangstadt und endend mit der Zielstadt, und daß es die Codes aller anderen Städte auf der Strecke genau einmal enthält. Mit diesem Wissen konnte Adleman das die Lösung repräsentierende Molekül mithilfe von Standardtechniken der Molekularbiologie isolieren. Dann überprüfte er manuell die Reihenfolge, in der sich die Bausteine zusammengefügt hatten und konnte so die richtige Sequenz von Städten bestätigen.
Das Entscheidende an Adlemans Berechnungsmethode ist die Verwendung von bestimmten materiellen Eigenschaften der DNA, um alle möglichen Kandidaten für die Lösung eines mathematischen Problems in einem Durchgang zu finden.
Das ist auch die Idee, die einem ganz unterschiedlichen Berechnungsproblem zugrundeliegt, indem man die fremde Welt der Quantenmechanik für die Ausführung von Berechnungen ausnutzt. Lassen Sie mich einen kurzen Blick auf diese Idee als letzten Punkt auf dieser Tour durch Nicht-Turing-Berechnungsmodelle werfen.
Quantencomputer
1982 veröffentlichte Richard Feynman einen Artikel mit dem Titel: "Simulating Physics with Computers". In diesem spekulativen Aufsatz schlug Feynman vor, die eigenartige Ambivalenz der quantenmechanischen Zustände der Teilchen wie der Elektronen zu benutzen, um eine Rechengeschwindigkeit zu erhalten, die bei weitem die der schnellstmöglichen konventionellen Computer übersteigt.
Ein Quantencomputer beruht auf der Fähigkeit eines Quantensystems, beispielsweise eines Atoms oder eines einzigen Photons, sich gleichzeitig in mehr als einem Quantenzustand zu bestimmen, was man in der Terminologie der Quantentheoretiker eine Superposition nennt. Zum Beispiel kann der Spin eines Photons gleichzeitig nach oben und nach unten ausgerichtet sein. Wenn wir diese beiden Zustände durch 0 und 1 repräsentieren, dann können auf der Basis der Superposition Berechnungen gleichzeitig mit beiden Werten vor sich gehen. Dann kann ein Quantencomputer, der n Photone oder Atome im Zustand der Superposition enthält, gleichzeitig eine Berechnung mit 2<FONT SIZE=-1>n Zahlen ausführen.. Das ist ein Grad der Parallelisierung, wie er für jeden gegenwärtigen klassischen Computer undenkbar ist.
Es gibt jedoch in diesem rosigen Bild einige Einschränkungen. Erstens begrenzt der Vorgang einer quantenmechanischen Messung - durch das Heisenbergsche Unbestimmtheitsprinzip - die Informationsmenge, die aus einem Quantencomputer bezogen werden kann. Zweitens sind Quanten-Superpositionen feine und zerbrechliche Dinge. Jeder Kontakt mit der Umgebung löst einen Prozeß aus, den man Dekohärenz nennt. Sie läßt die Superposition auf nur eine der möglichen Zustände zusammenbrechen, die das Quantenobjekt einnehmen kann. Dieser Zusammenbruch bringt natürlich den Vorteil eines Quantencomputers gegenüber einem klassischen Computer zum Verschwinden.
Man kann sich also berechtigterweise fragen, warum man sich überhaupt darum bemühen sollte, so etwas wie einen Quantencomputer zu bauen. Bis vor kurzem gab es keinen überzeugenden Beweis zur Unterstützung der Idee, daß ein Quantencomputer irgend etwas berechnen könnte, was nicht ebensogut mit einem klassischen Computer getan werden könnte. 1992 jedoch veröffentlichte Peter Shor von den AT&T Bell Laboratories einen quantenmechanischen Algorithmus zur Zerlegung großer Zahlen in ihre Primzahlen, der die Überlegenheit der Quantencomputer über ihre klassischen Gegenstücke demonstrierte. Die Faktorierung großer Zahlen hat eine nicht nur theoretische, sondern auch praktische Bedeutung in der Kryptographie, weswegen Shors Arbeit eine große Aufmerksamkeit auf sich zog. In allen bekannten Algorithmen zur Faktorierung wächst die Zeit, die man zum Finden der Primzahlkomponenten einer Zahl exponentiell mit der Größe dieser Zahl an. Für diejenigen, die eine Vorliebe für Zahlen haben, beträgt dieser Faktor annährend exp(L<FONT SIZE=-1>1/3), wobei L die Länge der in Frage stehenden Zahl ist. Shors Quantenalgorithmus benötigt eine Zeit proportional zu L<FONT SIZE=-1>2. Das ist eine erhebliche Zeitverkürzung gegenüber den klassischen Verfahren, wenn L groß wird. Sie ist tatsächlich so groß, daß sie das Faktorieren von einem "harten" zu einem "leichten" Berechnungsproblem werden läßt.
Die Frage, die sich auf die Durchführbarkeit von Shors Verfahren in der Praxis bezieht, wenn man einmal die nicht ganz einfache Frage beiseiteläßt, wie man wirklich eine Quantenmaschine baut, ist, ob der exponentiell schnelle Zusammenbruch der Superposition von Zuständen bei der Aussetzung an die Umgebung die exponentiell wachsende Zunahme der Berechnungsgeschwindigkeit bei der Faktorierung wieder auffressen würde. Vorsichtige Schätzungen von Shor, Wojciech Zurek und anderen haben gezeigt, daß die Quantenberechnungen bei der Faktorierung solange nützlich sind, wie eine niedrige Dekohärenzrate aufrechterhalten werden kann. Diese Ergebnisse beruhen grundsätzlich auf Shors Entdeckung von Quantenanaloga der Fehlerkorrekturcodes, die man in herkömmlichen Computern verwendet. Diese Standardschemata zur Fehlerkorrektur können aber bei Quanten nicht verwendet werden, weil sie implizieren, daß der Zustand des Computers gelesen wird, während die Berechnung vor sich geht und redundante Zustände geschaffen werden, um irrtümliche Berechnungen richtigzustellen. Die Schwierigkeit bei einer Quantensituation liegt darin, daß die Information in einem Quantensystem in dem Augenblick verschwindet, in dem man sie betrachtet.
Der Trick, ein Fehlerkorrekturschema zu schaffen, ist die Codierung jedes einzelnen Quantenbits als Kombination von Zuständen in einem multiplen Bitsystem. Shor breitet, mit anderen Worten, die Information in einem einzigen Bit über neun derartiger Bits aus. So kann die ursprüngliche Quanteninformation sogar für den Fall gesichert werden, daß ein Fehler in diesen neun Bits geschieht. Seth Lloyd vom MIT sagte, daß die Existenz solcher Fehlerkorrekturcodes "überraschend" gewesen seien: "Bevor Shor diese Idee entwickelte, hatte sie niemand für möglich gehalten." Ein von Lloyd jedoch angemerktes Problem liegt darin, daß eine Fehlerkorrektur, die eine eigene Berechnung ist, dasselbe Risiko enthält, Fehler zu begehen, wie die ursprüngliche Berechnung. Gegenwärtig hat niemand eine wirkliche Idee, wie man diese Schwierigkeit der zweiten Stufe in der Quantenberechnung lösen könnte.
Obgleich es hier nicht möglich ist, in die technischen Einzelheiten der unterschiedlichen Ansätze einzudringen, die von Wissenschaftlern für den wirklichen Bau eines Quantencomputers vorgeschlagen wurden, scheint es keine physikalischen oder logischen Hindernisse zu geben, die sich nicht überwinden ließen, sondern lediglich riesige ingenieurtechnische. Auch wenn es einige Zeit dauern könnte, bevor wir einen Quantencomputer auf unserem Schreibtisch stehen haben, der ohne weiteres Zahlen in der Länge von mehreren hundert Stellen faktoriert, ist die Möglichkeit solcher Maschinen evident. Und wenn uns die Geschichte der Technik eines lehrt, so ist es das, daß dann, wenn etwas einmal möglich geworden ist, es auch fast zwingend wird. Lassen Sie mich mit diesem Gedanken im Hinterkopf die Diskussion von Nicht-Turing-Modellen mit einigen Gedanken über die Grundlage für die überzogene Stellung abschließen, die das Turing-Modell in der modernen Theorie der Berechnung einnimmt.
Die Turing-Church-These
In der luftigen Welt der theoretischen Computerwissenschaft hat sich ein Prinzip in dem Maß durchgesetzt, daß wir die informelle Vorstellung, "eine Berechnung auszuführen", mit dem formalen Modell der Turing-Maschine gleichsetzen. Diese Annahme wurde mit dem Beiwort "These" geadelt und allgemein die Tuting-Church-These genannt. Wenn sie richtig ist, dann müssen alle Operationen oder Prozesse, die als Berechnung bezeichnet werden können, äquivalent damit sein, ein Programm auf einer Turing-Maschine laufen zu lassen. Das würde vor allem bedeuten, daß eine Quantität, wenn sie nicht auf einer Turing-Maschine berechenbar ist, überhaupt nicht berechenbar ist. Ende! Bis heute ist es wahr, daß niemand ein schlagendes Argument entwickelt hat, um zu zeigen, daß irgendein Modell der Berechnung eine größeere Gruppe von Objekten als das Turing-Maschinen-Modell berechnen kann. Aber das heißt noch lange nicht, daß kein solches Modell existiert.
Nur um zu demonstrieren, wie extrem die Turing-Church-These ist, hat der Mathematiker Ian Stewart vor ein paar Jahren halb scherzhaft die Idee eines sogenannten Sich Schnell Beschleunigenden Computers (Rapidly-Accelerating Computer - RAC) vorgeschlagen. Er wollte genau zeigen, woran es bei Computern liegt, daß so etwas wie das Halteproblem und unberechenbare Zahlen entstehen. Das Problem ist grundsätzlich die Annahme, daß eine fixierte, endliche Zeit nötig ist, um einen einzigen Schritt in einer Berechnung auszuführen. Für seinen idealisierten Computer nahm Turing einen unendlich großen Speicher an. Stewart denkt sich andererseits den RAC so, daß sich dessen Uhr in einer exponentiellen wachsenden Geschwindigkeit mit einem Takt von 1/2, 1/4, 1/8 ... Sekunden beschleunigt. So kann der RAC eine infinite Zahl von Berechnungsschritten in eine einzige Sekunde packen. Eine solche Maschine wäre ein wunderbarer Anblick, da sie der algorithmischen Komplexität eines jeden ihr gestellten Problems völlig gleichgültig gegenüberstände. Auf dem RAC läuft alles in einer begrenzten Zeit.
Der RAC kann das Unberechenbare berechnen. Er könnte beispielsweise leicht das Halteproblem lösen, indem er eine Berechnung in beschleunigter Zeit ausführt und nur dann einen Schalter betätigt, wenn das Programm zu einem Ende kommt. Da der ganze Ablauf nicht mehr als eine Sekunde Zeit benötigt, müssen wir nur noch schauen, ob der Schalter betätigt wurde. Der RAC könnte auch berühmte mathematische Puzzles wie Goldbachs Vermutung (jede Zahl, die größer als 2 ist, ist die Summe von zwei Primzahlen) beweisen oder widerlegen. Noch beeindruckender ist, daß die Maschine alle möglichen Theoreme beweisen könnte, indem sie jede logisch gültige Deduktionskette aus den Axiomen der Mengentheorie durchläuft. Und wenn jemand an die klassische Newtonsche Mechanik glaubt, dann gibt es nicht einmal ein theoretisches Hindernis auf dem Weg, wirklich einen RAC zu bauen.
In Newtons Welt können wir den RAC mit einem klassischen dynamischen System modellieren, das eine Ansammlung interagierender Teilchen enthält. Z. Xia und J. Gerver haben eine Möglichkeit gezeigt, dies zu tun. Die in der Maschine ablaufenden Vorgänge werden hier durch Zusammenstöße von Bällen ausgeführt, die sich exponentiell beschleunigen. Weil die klassische Mechanik den Geschwindigkeiten solcher Teilchen keine obere Grenze setzt, ist es möglich, die Zeit in den Geschwindigkeitsgleichungen zu beschleunigen, in dem sie einfach so parameterisiert, daß eine unbegrenzte subjektive Zeit in einer begrenzten objektiven Zeitspanne abläuft. Dadurch kommen wir zu einem System klassischer dynamischer Gleichungen, die die Operationen des RAC nachahmen. Auf diese Weise kann ein solches System das Unberechenbare berechnen und das Unentscheidbare entscheiden.
Natürlich ist der RAC ebenso wie Turings Maschine mit einem unendlich großen Speicher in der wirklichen Welt unmöglich. Das Problem ist, daß es auf der Ebene von wirklichen materiellen Gegenständen wie logischen Gattern und Schaltkreisen für die Geschwindigkeit der Informationsübermittlung eine theoretische obere Grenze gibt. Wie Einstein gezeigt hat, kann kein materielles Objekt schneller als die Lichtgeschwindigkeit sein. Daher gibt es keinen RAC und folglich keine Maschinen, das Unvollständige zu vervollständigen.
Doch der Umstand, daß wir niemals einen RAC bauen können werden, schließt in keiner Weise die Möglichkeit aus, daß nicht eine analoge Maschine wie ein DNA-Computer oder ein Quantencomputer realisiert werden könnte, mit dem wir die Turing-Grenze überschreiten und folglich das Unberechenbare berechnen könnten.
Aus dem Englischen übersetzt von Florian Rötzer